![You are currently viewing Machine Learning Operations [MLOps]](https://connectjaya.com/wp-content/uploads/2021/07/Slide1.jpg)
MLOps is enabling machine learning applications in production at scale.
Through 2023, atleast 50% of the IT leaders will scuffle to move their AI predictive projects from proof of concept to production maturity.

Lets understand the challenges og Machine Learning Operations….

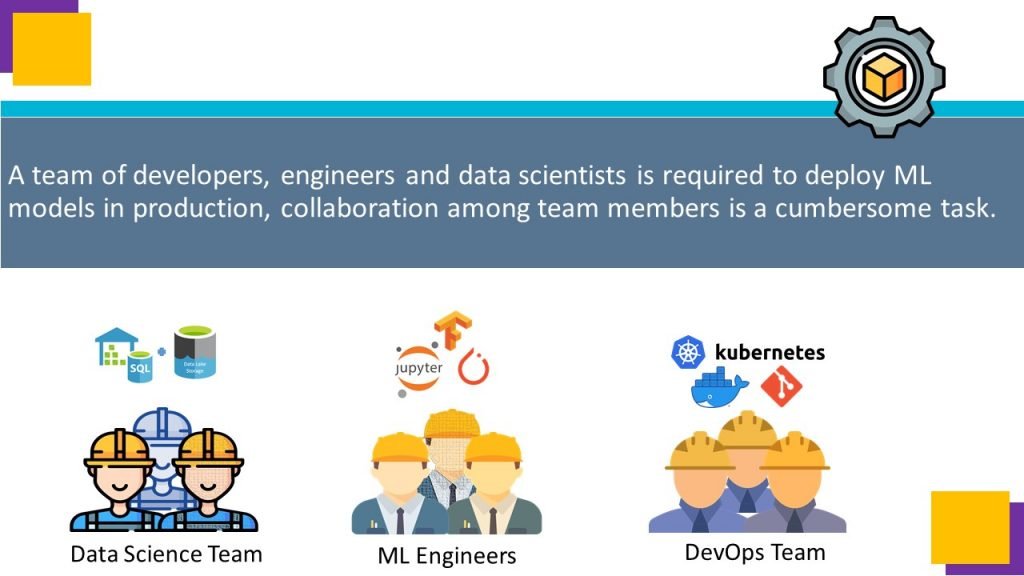
Usually data science team works in a silo, separately from Engineering, Development and DevOps team, who are responsible for converting manual process of model training and updation into production ready Machine learning pipelines.
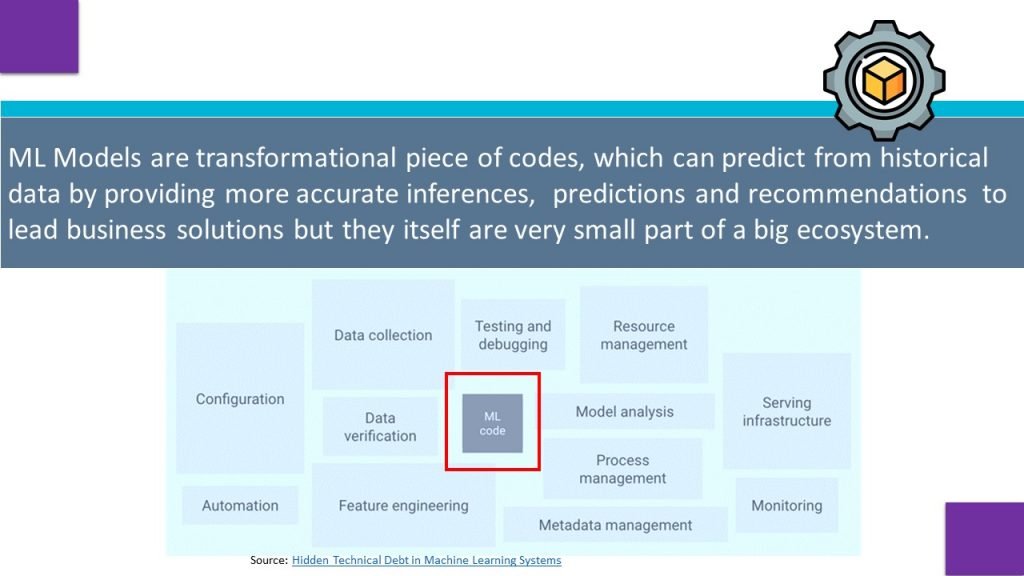
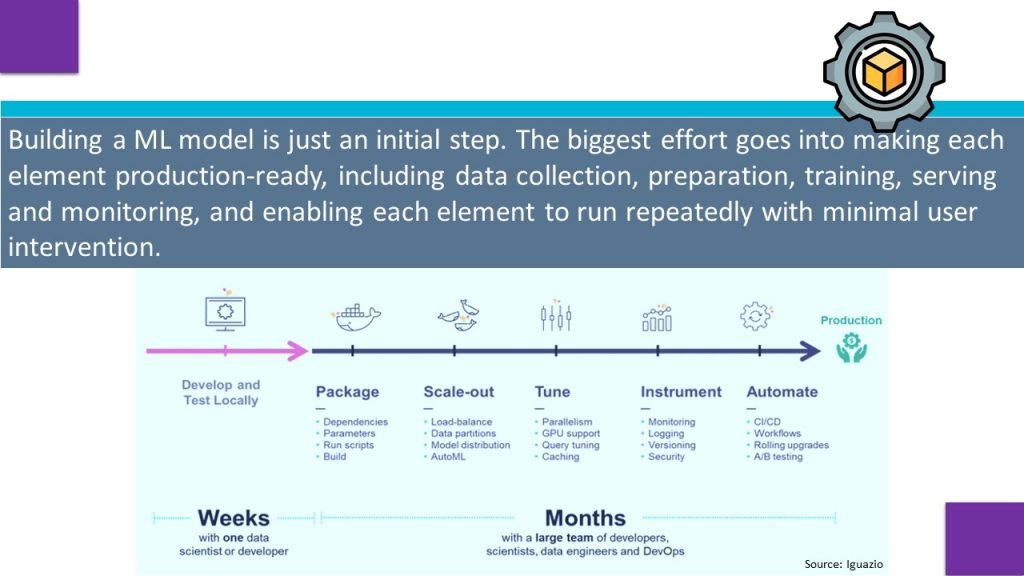
Models ingest data and produce inferences that are used in making decisions. Increasingly, the inferences produced by models are consumed by software applications and used to partially or fully automate business decisions.
How DevOps Turned into MLOps
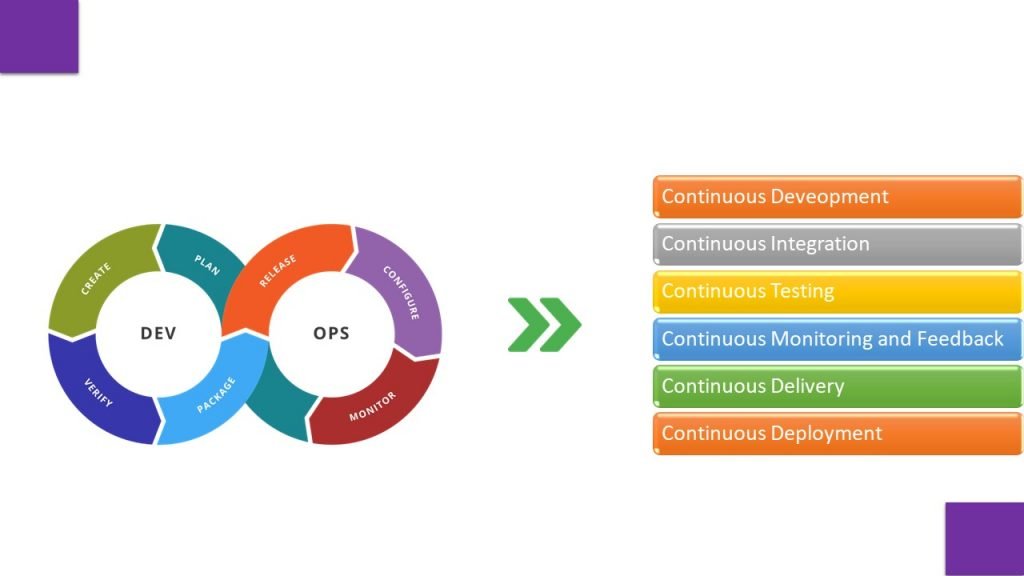
The DevOps process flow is all about agility and automation. Each phase in the DevOps lifecycle focuses on closing the loop between development and operations and driving production through continuous development, integration, testing, monitoring and feedback, delivery, and deployment.
Machine Learning models need continuous improvement for better prediction and accuracy, so integration of DevOps operations with Machine Learning Lifecycle results in MLOps.
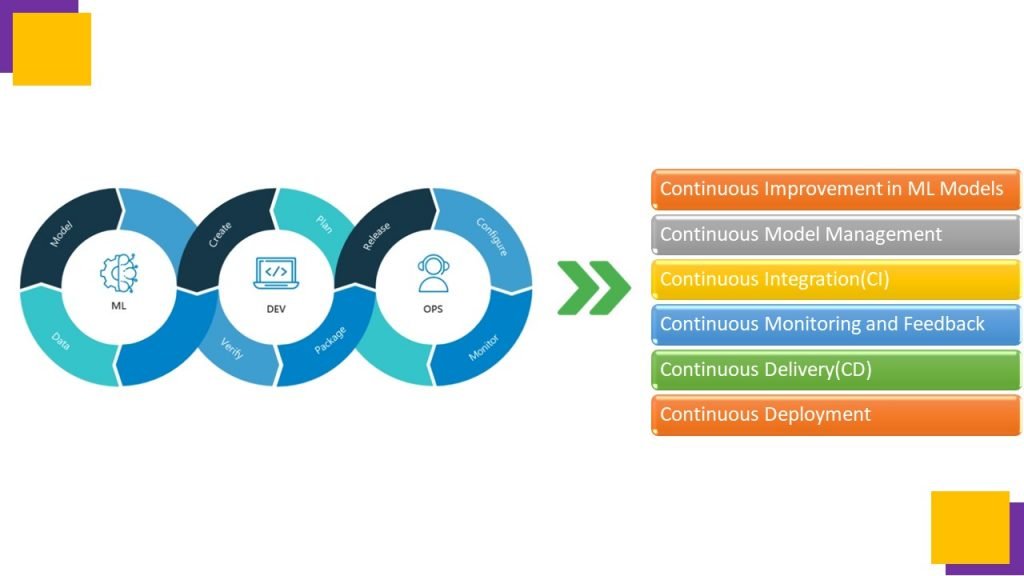
monitor the quality of machine learning models in production
Manual ML Pipeline
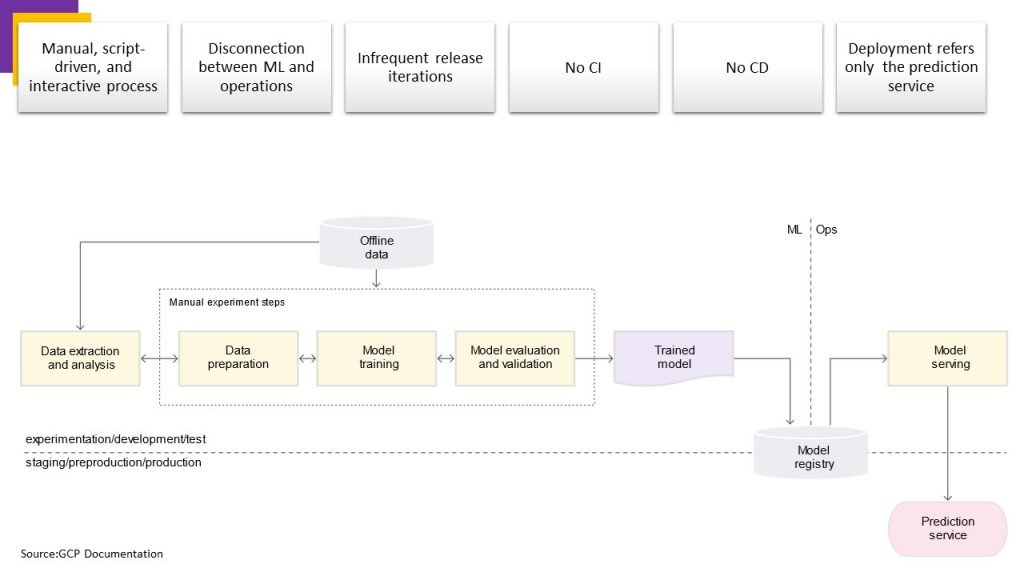
Many teams have data scientists and ML researchers who can build state-of-the-art models, but their process for building and deploying ML models is entirely manual. This is considered the basic level of maturity, or level 0.
Manual, script-driven, and interactive process: Every step is manual, including data analysis, data preparation, model training, and validation. It requires manual execution of each step, and manual transition from one step to another.
Disconnection between ML and operations: The process separates data scientists who create the model and engineers who serve the model as a prediction service.
Infrequent release iterations: The process assumes that your data science team manages a few models that don’t change frequently—either changing model implementation or retraining the model with new data. A new model version is deployed only a couple of times per year
No CI: Because few implementation changes are assumed, CI is ignored. Usually, testing the code is part of the notebooks or script execution.
No CD: Because there aren’t frequent model version deployments, CD isn’t considered.
Deployment refers to the prediction service: The process is concerned only with deploying the trained model as a prediction service (for example, a microservice with a REST API), rather than deploying the entire ML system
Lack of active performance monitoring: The process doesn’t track or log the model predictions and actions, which are required in order to detect model performance degradation and other model behavioral drifts.
ML Pipeline For Continuous Training
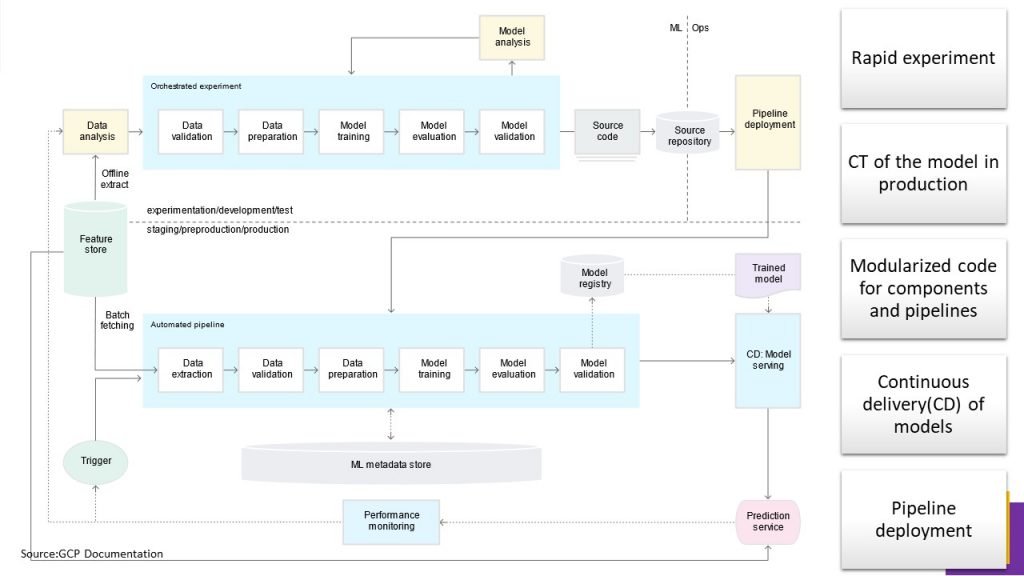
Rapid experiment: The steps of the ML experiment are orchestrated. The transition between steps is automated, which leads to rapid iteration of experiments and better readiness to move the whole pipeline to production.
CT of the model in production: The model is automatically trained in production using fresh data based on live pipeline triggers, which are discussed in the next section.
Experimental-operational symmetry: The pipeline implementation that is used in the development or experiment environment is used in the preproduction and production environment, which is a key aspect of MLOps practice for unifying DevOps.
Modularized code for components and pipelines: To construct ML pipelines, components need to be reusable, composable, and potentially shareable across ML pipelines.
Continuous delivery of models: An ML pipeline in production continuously delivers prediction services to new models that are trained on new data. The model deployment step, which serves the trained and validated model as a prediction service for online predictions, is automated.
Pipeline deployment: In level 0, you deploy a trained model as a prediction service to production. For level 1, you deploy a whole training pipeline, which automatically and recurrently runs to serve the trained model as the prediction service.
CI/CD Pipeline Automation
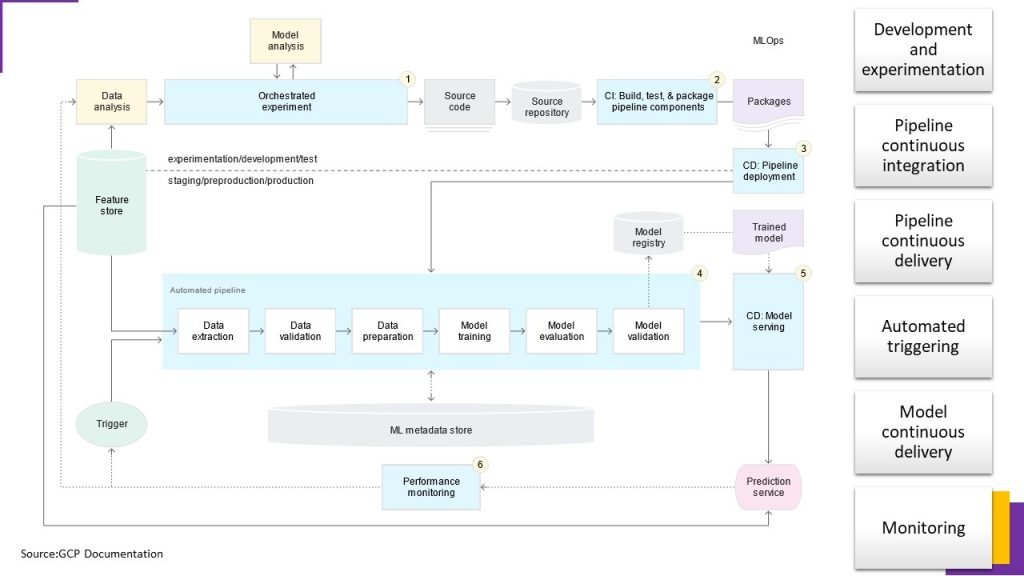
For a rapid and reliable update of the pipelines in production, you need a robust automated CI/CD system. This automated CI/CD system lets your data scientists rapidly explore new ideas around feature engineering, model architecture, and hyperparameters. They can implement these ideas and automatically build, test, and deploy the new pipeline components to the target environment.
This MLOps setup includes the following components: •Source control •Test and build services •Deployment services •Model registry •Feature store •ML metadata store •ML pipeline orchestrator
In this setup, the pipeline and its components are built, tested, and packaged when new code is committed or pushed to the source code repository. Besides building packages, container images, and executables, the CI process can include Unit testing your feature engineering logic, Testing that your model training converges, Testing that your model training doesn’t produce NaN values due to dividing by zero or manipulating small or large values, Testing integration between pipeline components
Continuous Delivery: In this level, your system continuously delivers new pipeline implementations to the target environment that in turn delivers prediction services of the newly trained model.
For rapid and reliable continuous delivery of pipelines and models, you should consider Verifying the compatibility of the model with the target infrastructure before you deploy your model, Testing the prediction service by calling the service API with the expected inputs, and making sure that you get the response that you expect, Testing prediction service performance, which involves load testing the service to capture metrics such as queries per seconds (QPS) and model latency.
Validating the data either for retraining or batch prediction etc.
1.Development and experimentation: You iteratively try out new ML algorithms and new modeling where the experiment steps are orchestrated. The output of this stage is the source code of the ML pipeline steps that are then pushed to a source repository.
2.Pipeline continuous integration: You build source code and run various tests. The outputs of this stage are pipeline components (packages, executables, and artifacts) to be deployed in a later stage.
3.Pipeline continuous delivery: You deploy the artifacts produced by the CI stage to the target environment. The output of this stage is a deployed pipeline with the new implementation of the model.
4.Automated triggering: The pipeline is automatically executed in production based on a schedule or in response to a trigger. The output of this stage is a trained model that is pushed to the model registry.
5.Model continuous delivery: You serve the trained model as a prediction service for the predictions. The output of this stage is a deployed model prediction service.
6.Monitoring: You collect statistics on the model performance based on live data. The output of this stage is a trigger to execute the pipeline or to execute a new experiment cycle.
Machine Learning Development Life Cycle [MLDLC]
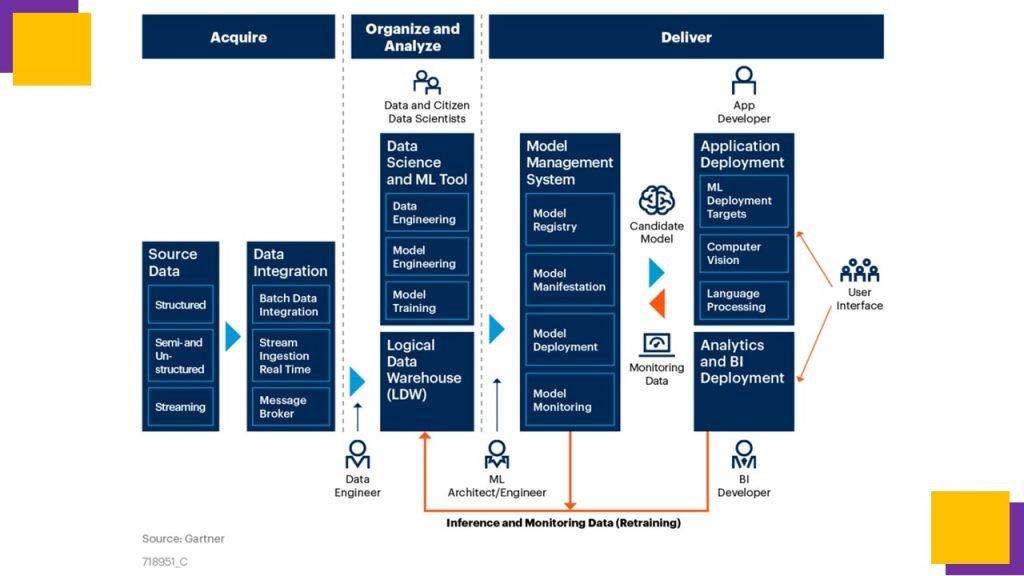
This is the architecture to operationalize ML DLC
Case Studies
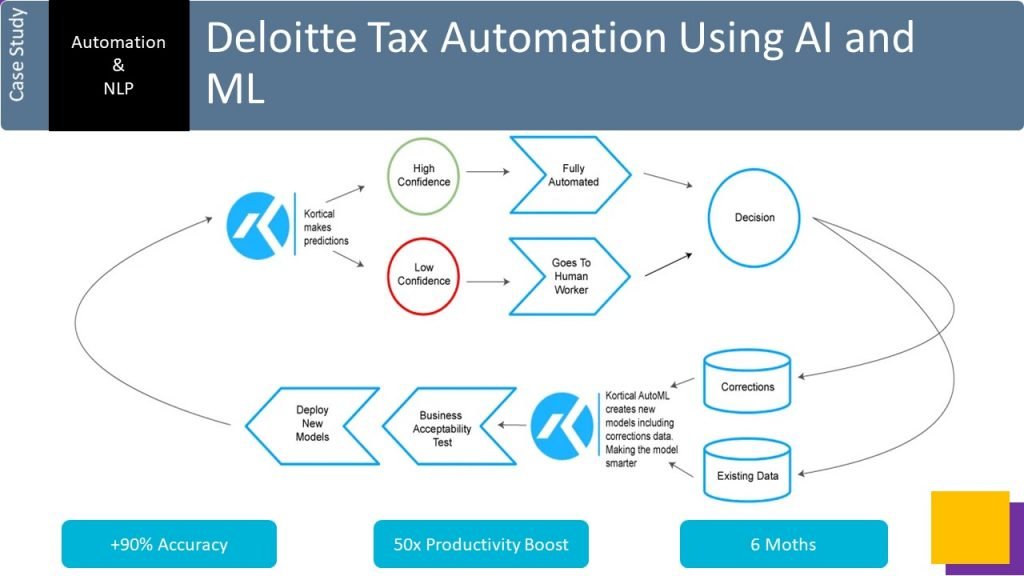
AI makes predictions -> User corrects or accepts with low confidence predictions – > data fed back into Kortical -> AutoML -> Business defined acceptability tests -> deploy -> back to predict
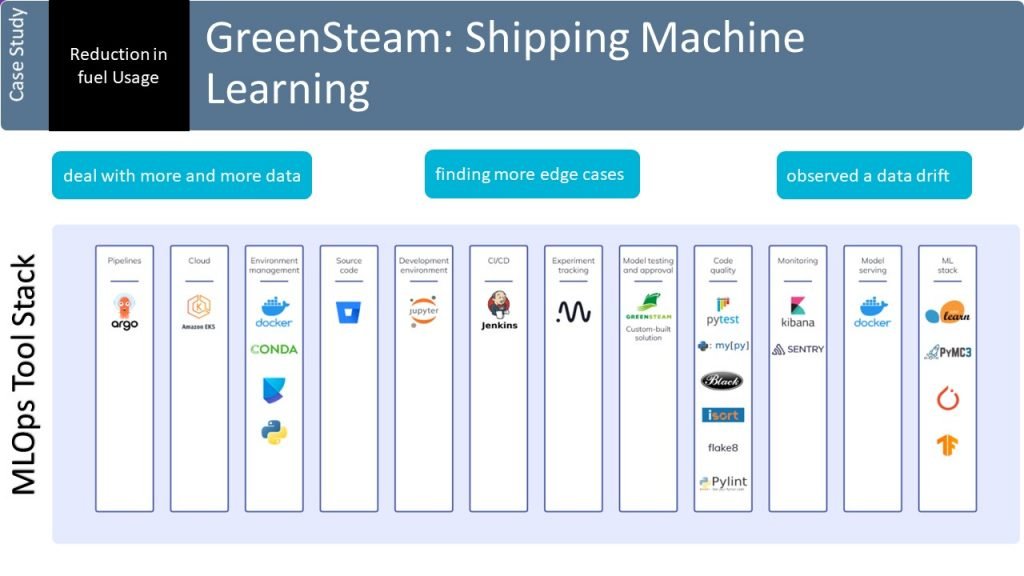
GreenSteam is a company that provides software solutions for the marine industry that help reduce fuel usage.
Industry Shift from MLOps to ModelOps
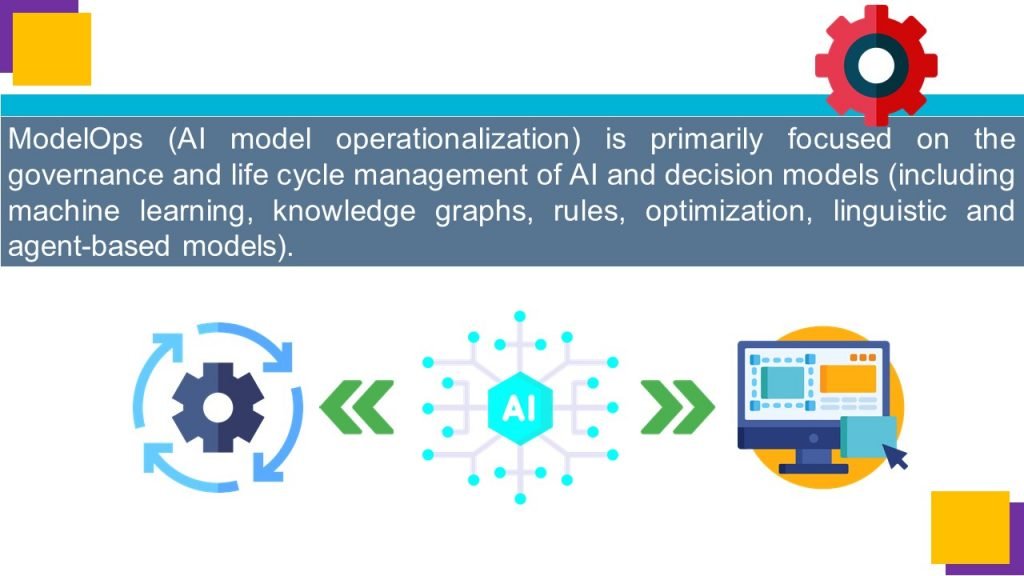
MLOps deals with the operationalization of ML models whereas ModelOps refers to the operationalization of all AI models.
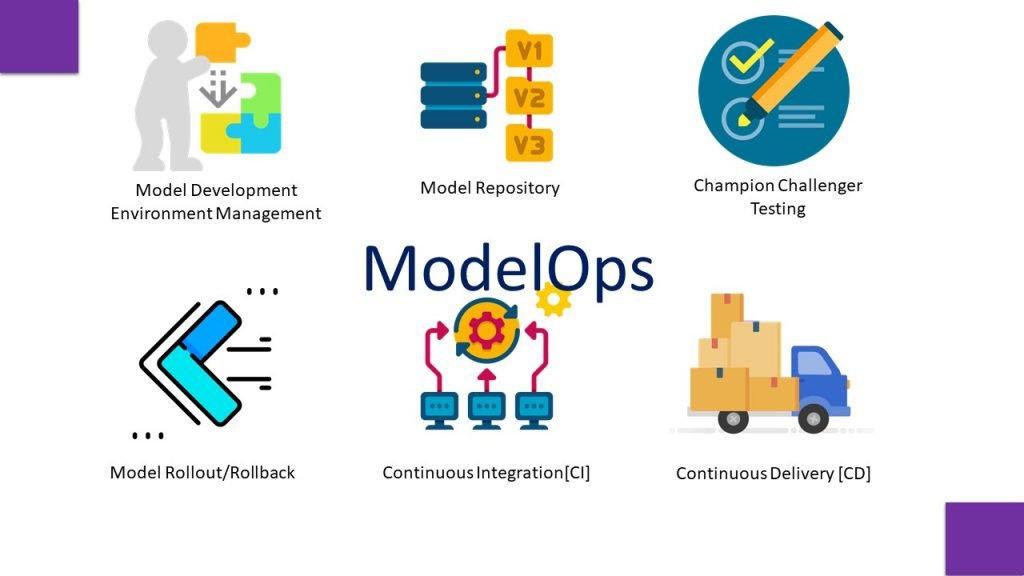
Core capabilities include the management of model development environments, model repository, champion-challenger testing, model rollout/rollback, and CI/CD integration.
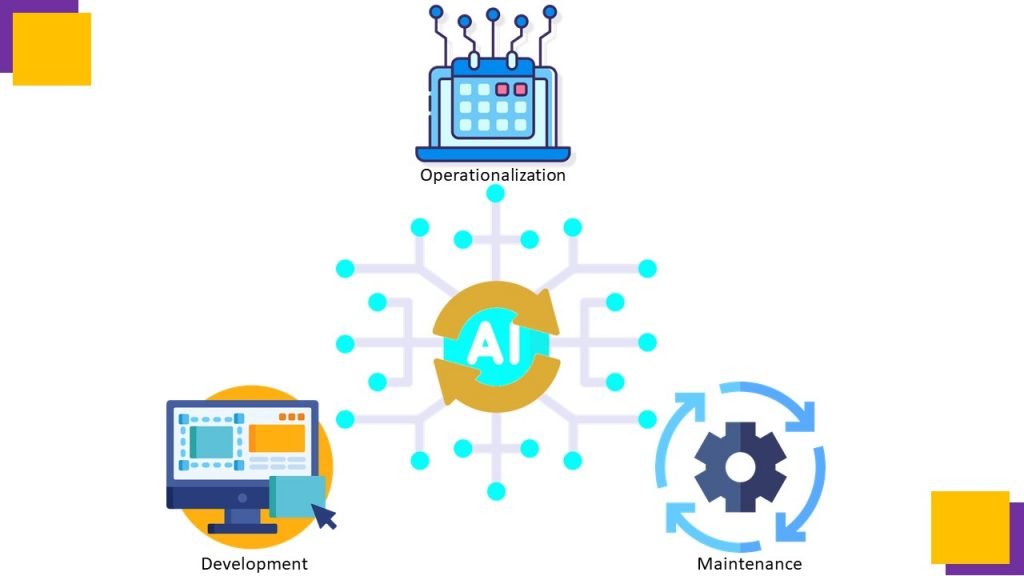
ModelOps enables the retuning, retraining or rebuilding of AI models, providing an uninterrupted flow between the development, operationalization and maintenance of models within AI-based systems.
ModelOps provides business domain experts autonomy to assess the quality (interpret the outcomes and validate KPIs) of AI models in production and facilitates the ability to promote or demote AI models for inferencing without a full dependency on data scientists or ML engineers.
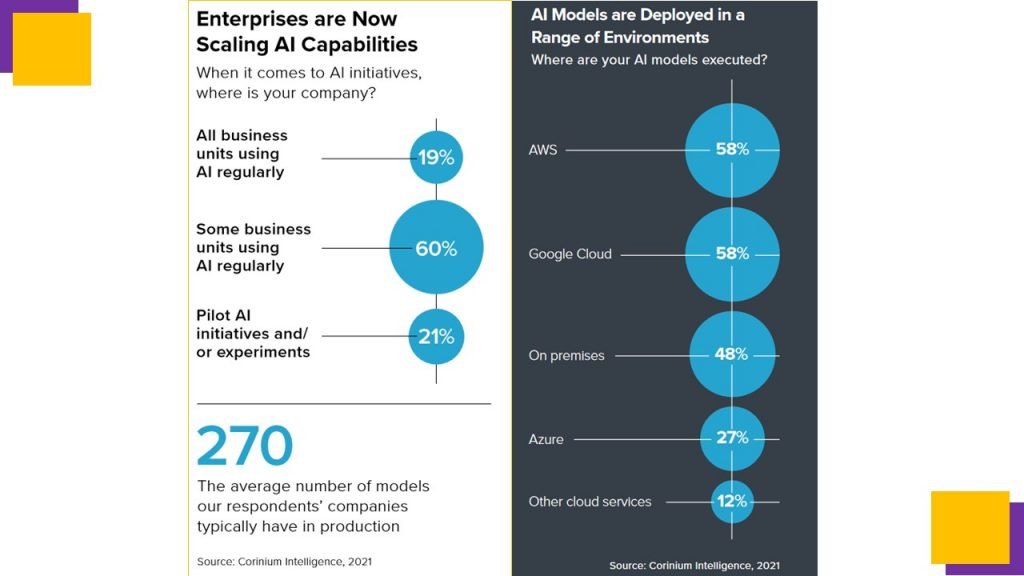
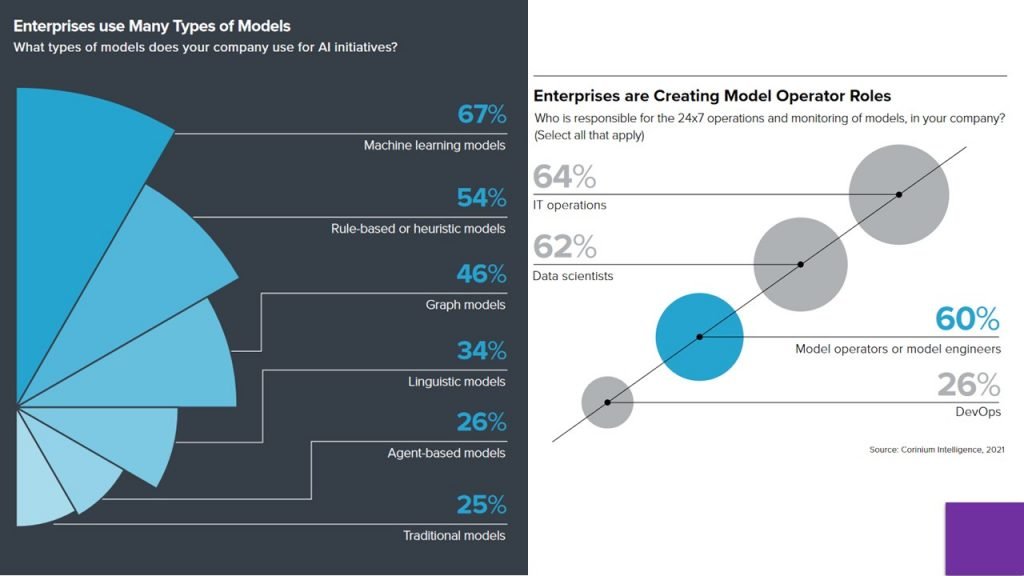
Statistics about ModelOps

{kind=link}