First, make sure you have installed the putty to access the terminal and WinSCP for transferring files.
Step 1: Create tmux session
$ tmux new -s session-name # create new session
$ Ctrl+b then d to leave the current session
$ tmux attach -t session-name # attach to previous session , ex. $ tmux attach -t phdwork
$ tmux list-sessions # list of all sessions
Step 2 Load Docker on GPU
$ NV_GPU=’1′ nvidia-docker run –rm -it -v /home/dgxusername/:/home/dgxusername/ nvcr.io/nvidia/tensorflow:17.11
In the above command ‘1’ is the GPU number
Ctrl+p and Ctrl+q to exit the current container, Container will be lost.
Other useful commands
$ docker images //list of all docker images
$ nvidia-smi //list usage of all GPU’s
$ tar xvf Python.tar.xz
Step 3 Execute your program
After loading the docker, change the working directory to the directory species while loading the docker and run your program.
$ cd /home/dgxusername/
$ python program.py
You can install any missing library using pip
$ pip install matplotlib
Step 4 Load docker with the named session (optional)
$ NV_GPU=’1′ nvidia-docker run -p 5052:8888 –name tejadocker1 –rm -it -v /home/dgxusername/:/home/dgxusername nvcr.io/nvidia/tensorflow:17.11
$ nvidia-docker start tejadocker1
$ nvidia-docker attach tejadocker1
$ python3 demo.py
$ –shm-size=25G
Step 5 Check OS version installed in Docker
lsb_release -sirc
Ubuntu
16.04
xenial
Step 6 Check python version installed in Docker
python –version
Step 7 Install Anaconda on Docker for user dgxphd05
RUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
Issue: RUN: command not found
The “Command not found” error is caused by the fact that Linux is unable to find on your system a command you try to execute. When you run a command Linux looks for binaries in the list of directories specified in the PATH environment variable, this allows you to execute a command without specifying its full path.
Step 8 How to see paths set in environment variable
ls -al /usr/bin/ch*
Step 7 didnt worked for me, So i downoaded minniconda form anaconda website. and installed it using following command
bash Miniconda3-latest-Linux-x86_64.sh
Still conda create was not working, hence i set the environment variable using following command.
export PATH=/home/dgxphd05/miniconda3/bin:$PATH
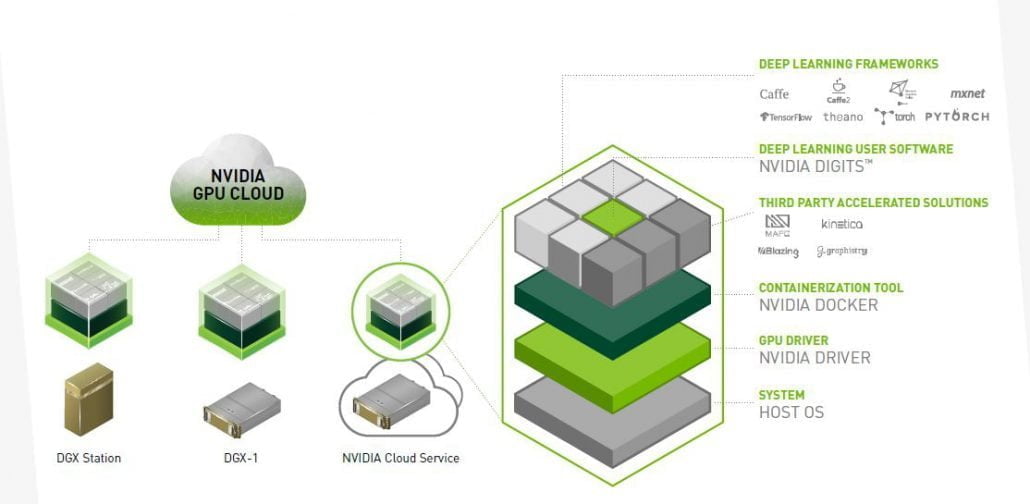
CPU VS GPU

1.2. CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
In November 2006, NVIDIA® introduced CUDA®, a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU.
CUDA comes with a software environment that allows developers to use C++ as a high-level programming language. As illustrated by Figure 2, other languages, application programming interfaces, or directives-based approaches are supported, such as FORTRAN, DirectCompute, OpenACC.

Using CUDA with PyTorch: a step-by-step example
Now you understand the basics of PyTorch, CUDA and their key capabilities. You also understand PyTorch CUDA support. Now let’s step away from the theory and discuss more practical applications of PyTorch and CUDA.. This section will cover how to use CUDA with PyTorch. I will try to be as precise as possible and try to cover every aspect you might need when working on your ML project.
What will be covered in this section:
- How to check the availability of CUDA?
- How to get additional information about the CUDA device?
- How to work on multiple CUDA devices?
- How to train a PyTorch model on a GPU?
- How to parallelize the training process?
- How to run a PyTorch model on a GPU?
Also, I have prepared a notebook that can be accessed via Google Collab to support this article. In this notebook, I am using MobileNet V3 architecture to solve a classification problem on the CIFAR10 dataset.
You will find everything mentioned in this article below in the notebook. Do not forget to turn on the GPU as the notebook will crash without it. Please feel free to experiment and play around as there is no better way to master something than practice.
Let’s jump in.
Check availability of CUDA
To start with, you must check if your system supports CUDA. You can do that by using a simple command.
torch.cuda.is_available() This command will return you a bool value either True or False. So, if you get True then everything is okay and you can proceed, if you get False it means that something is wrong and your system does not support CUDA. Please make sure that you have your GPU turned on (in case you are using Google Collab) or go to the web to find out any other internal issues.
It is a crucial moment as this command will check if your GPU is available and the required NVIDIA drivers and CUDA libraries are properly installed. Please do not ignore this step as it might save you a lot of time and unnecessary frustrations.
Additional information about CUDA device
If you passed the previous step, it is time to figure out some useful information about the CUDA device you are currently on. The methods mentioned below are quite useful, so please keep them in mind when working with CUDA as they might help you figure out the problem if something goes wrong.It is worth mentioning, that the methods are available only on GPUs as that is exactly what CUDA works with.
Let’s start with simple information about the CUDA device like an id and name. There are simple methods for finding both of them.
torch.cuda.current_device() #returns you the ID of your current device
torch.cuda.get_device_name(ID of the device) #returns you the name of the device
Also, you may find some useful information about the memory usage of the device.
torch.cuda.memory_allocated(ID of the device) #returns you the current GPU memory usage by tensors in bytes for a given device
torch.cuda.memory_reserved(ID of the device) #returns you the current GPU memory managed by caching allocator in bytes for a given device, in previous PyTorch versions the command was torch.cuda.memory_cached
Moreover, you can actually release all unoccupied cached memory currently held by the caching allocator so that those can be used in other GPU applications using a simple method.
torch.cuda.empty_cache() Still, you must remember that this command will not free the occupied GPU memory, so the amount of GPU memory available for PyTorch will not be increased. Just keep this in mind.
Working with multiple CUDA devices
All right, let’s assume that you have multiple devices that are CUDA compatible. Of course, you can use only one of them but, if you have the ability, you should probably use all of them. Firstly, using all of them will increase performance.. Secondly, CUDA allows you to do it quite seamlessly.
In general, there are two basic concepts that you might want to follow if you want to maximize the potential of multiple GPUs:
- Simply use each GPU (device) for its own purpose (task or application) – the basic but quite effective concept
- Use each GPU to do a part of a project – for example, in the ensemble case where you need to train a variety of models
Overall, the workflow is quite simple. Firstly, you need to figure out the ID of a specific CUDA device that you have using the methods mentioned above. Secondly, you just need to allocate tensors to a specific device or change the default device.
If you’re considering allocating tensors to various code devices, please keep in mind that in general, all tensors are allocated to your default (current) device that has ID equal to zero (0). Still, you can easily allocate a tensor to any CUDA device if you specify the ID of a destination device.
cuda1 = torch.device(‘cuda:1’) #where 1 is the ID of specific device
tensor = torch.Tensor([0.,0.], device = cuda1)
tensor = torch.Tensor([0.,0.]).to(cuda1)
tensor = torch.Tensor([0.,0.]).cuda(cuda1)
As you may see there are three ways to allocate a PyTorch tensor to a specific device. Feel free to use any of them as all of them are legit. As mentioned above you cannot perform cross-GPU operations, so please use tensors from one device. Also, be aware that the tensor’s operation result will be allocated at the same device as the tensors.
Moving on to changing the default CUDA device. You can easily do this with a simple method.
torch.cuda.set_device(1) #where 1 is the ID of device By doing that you will switch the default CUDA device and from that point, every tensor will be allocated on a new device.
Also, if you have multiple GPUs and for some reason do not want to use some of them you can make a specific GPU invisible using an environment variable.
import os
os.environ[“CUDA_VISIBLE_DEVICES”] = “1,2,3” #where 1, 2, 3 are the IDs of CUDA devices that will be visible (in this example device with the 0 ID is invisible)
Training a PyTorch model on a GPU
Now that you know how to work with tensors and CUDA devices (GPUs), it is finally time to talk about training a PyTorch neural network on GPU. To tell the truth, it’s actually not so difficult. If you have checked the availability of the CUDA device, you will not face any problem in this step.
You might want to reference the “MobileNetV3 (small)” and “Training preparation” sections of the notebook I have prepared for you as it covers pretty much everything you need to know.
So, to train a PyTorch model on a GPU you need to:
- Code your own neural network architecture or use a pre-built one from torchvision.models
- Allocate your model to the GPU
net = MobileNetV3() #net is a variable containing our model
net = net.cuda() #we allocate our model to GPU
3. Start training
Yes, it is that simple. Fortunately, PyTorch does not require anything complicated to carry out this task, unlike some other frameworks.
From now on your model will store on the GPU and the training process will be executed there as well. However, please do not forget that you must allocate your data on the GPU as well or you will face errors. You can do that as described in the “Working with multiple CUDA devices section”.
Still, if you want to make sure that your model is truly on the GPU you must check whether its parameters are on GPU or not.
next(net.parameters()).is_cuda #returns a bool value, True - your model is truly on GPU, False - it is not
If you are interested in the general training process for PyTorch models please refer to the “Training” section of my notebook as I have manually coded the training process there.
Parallelizing the training process
As for the parallelization, in PyTorch, it can be easily applied to your model using torch.nn.DataParallel.
The general idea is splitting the input across the specified CUDA devices by dividing the batch into several parts. In the forward pass, the model is replicated on each device, and each replica handles a portion of the input. During the backwards pass, gradients from each replica are summed into the original model.
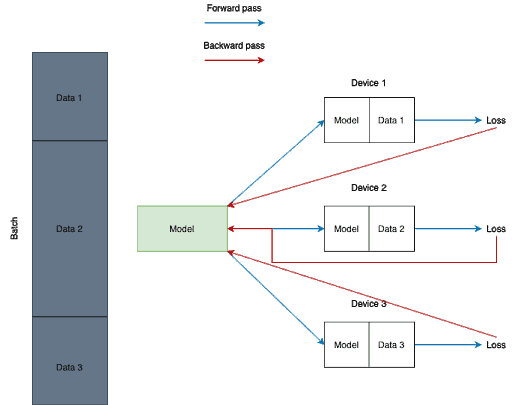
Still, in terms of code, it is very simple. Below you can find a piece of code where I form a list of GPUs to make them CUDA visible devices, allocate my model to GPU and use DataParallel to make my training process parallelized.
GPU = 0, 1
gpu_list = ''
multi_gpus = False
if isinstance(GPU, int):
gpu_list = str(GPU)
else:
multi_gpus = True
for i, gpu_id in enumerate(GPU):
gpu_list += str(gpu_id)
if i != len(GPU) - 1:
gpu_list += ','
os.environ['CUDA_VISIBLE_DEVICES'] = gpu_list
net = net.cuda()
if multi_gpus:
net = DataParallel(net, device_ids = gpu_list)Running a PyTorch model on GPU
So, after you finished training you might want to test your model on some test dataset. That is the point where you need to figure out how to run your model on a GPU.
Luckily we already know everything we need to do that. You can find a simple example of loading a PyTorch model from the checkpoint and allocating it to a CUDA device.
cuda = torch.cuda.is_available()
net = MobileNetV3()
checkpoint = torch.load(‘path/to/checkpoint/)
net.load_state_dict(checkpoint[‘net_state_dict’])
if cuda:
net = net.cuda()
net.eval()
result = net(image) #remember that image must be allocated to GPU as well
Best tools to manage PyTorch models
In the previous section, we have discussed how to use CUDA with PyTorch and now you should not face obstacles when using CUDA for your PyTorch project. Still, it is considered common sense to have a specific tool to back you up.
Sometimes when you dive into a project, you may quickly realize that you’re drowning in an ocean of Python scripts, data, algorithms, functions, updates, and so on. At some point, you just lose track of your experiments, and can’t even say which script or update led to the best result. That is why it is very convenient to have a tool that will help you with experiment tracking and model management.
There are many MLOps tools. There are even articles and lists that cover this topic. Still, I want to mention some of them here so you are able to feel the variety and decide if you need a tool at all.
I am sure you are all familiar with the first tool. It is Tensorboard.
In my experience it is the most popular tracking and visualization tool out there. It can be used with PyTorch but it has some pitfalls. For sure, it is an easy-to-start tool but its tracking functionality seems limited. There are tools that provide way more capabilities.
Still, it has nice and complete documentation, so you might give it a shot.
One way to make Tensorboard even easier to use is with cnvrg.io. cnvrg.io has Tensorboard embedded into the platform to help track and manage your projects without having to switch between platforms. In addition, cnvrg.io is natively integrated to PyTorch, that allows data scientists to easily parallelize computations across nodes. Not only that but cnvrg.io is natively integrated with Nvidia’s NGC containers so data scientists can instantly launch PyTorch in one click with optimized performance.
Overall, it is a very powerful tool with awesome and easy to navigate through documentation. Moreover, it has valuable tutorials for using PyTorch, so you should have no problem setting things up. Please refer to the official documentation if you want to learn more about the platform as there is too much to talk about.
That is why cnvrg is a good fit as the project management tool for any DL project.
The third tool I want to mention here is Azure Machine Learning. It is a cloud-based machine learning lifecycle platform developed by Microsoft.
To tell the truth, it is a really popular tool that is used by some large IT companies. It is really good at versioning and experiment tracking and has well-structured documentation with loads of simple examples.
However, due to its end-to-end focus and lack of valuable advanced tutorials the entry threshold is rather high. You really need to learn the tool before you will use it effectively. That is why please use Azure Machine Learning only if you are ready to spend some time studying the instrument.
Of course, it is impossible to cover all the variety of different MLOps tools. I have mentioned only those that I frequently use myself. So, please feel free to investigate the topic and you will eventually find the tool that suits you and your project the best
Best practices, tips, and strategies
Throughout this article I mentioned plenty of useful tips and techniques, so let’s summarize them into a list:
- Pick PyTorch as a DL framework if you want a tool that is effective, fast, and convenient to use
- Always train on GPUs
- If you are working in Kaggle kernels or Google Collab do not forget they support GPU usage but they are turned off by default. Please enable GPU accelerators there
- It is super easy and effective to use CUDA when working with a PyTorch model
- Do not forget about CUDA key capabilities such as tensors creation and usage, parallelizations, and streams
- Remember that it’s always good practice to keep track of GPU memory usage when using CUDA as it will help you avoid some unfortunate mistakes
- Do not forget to check PyTorch’s official documentation as it has plenty of simple examples and valuable tutorials that must cover the majority of your questions
- It’s recommended to use more than one GPU for better performance (if you have the option)
- Do not forget to parallelize the training process if possible
- Do not underestimate the power of community and forums. In many cases, if you face an error you can simply Google it and find the answer
- It is always better to use some MLOps tool to help you with model management, experiment tracking, resource management and DevOps automation
- You must keep an eye on PyTorch and CUDA updates as some things might change
Final Thoughts
Hopefully this tutorial will help you succeed and use your GPUs more effectively in your next Deep Learning project.
To summarize, we started with some theoretical information about using PyTorch and CUDA and went through a step-by-step guide on how to use CUDA when working on a PyTorch model. Also, we covered some PyTorch model management tools. Lastly, we talked about some tips you may find useful when working with CUDA.
If you enjoyed this post, a great next step would be to start building your own Deep Learning project with all the relevant tools. Check out tools like:
- PyTorch as a DL framework,
- CUDA as GPU accelerator,
- cnvrg for model management and experiment tracking
For extra support, you can access the Notebook for further code and documentation.
Get a list of the currently running sessions
To attach to a session first, you need to find the name of the session. To get a list of the currently running sessions type:
tmux lsBelow are some most common commands for managing Tmux windows and panes:
Ctrl+bcCreate a new window (with shell)Ctrl+bwChoose window from a listCtrl+b0Switch to window 0 (by number )Ctrl+b,Rename the current windowCtrl+b%Split current pane horizontally into two panesCtrl+b"Split current pane vertically into two panesCtrl+boGo to the next paneCtrl+b;Toggle between the current and previous paneCtrl+bxClose the current pane
Thanks for reading, and happy training!
System Specification at my College: Bennett University(Times of India Group)


Resources
- https://www.analyticsvidhya.com/blog/2017/05/gpus-necessary-for-deep-learning/
- https://pytorch.org
- https://developer.nvidia.com/cuda-zone
- https://pytorch.org/docs/stable/cuda.html
- https://cnvrg.io
- https://www.tensorflow.org/tensorboard?hl=en
- https://azure.microsoft.com/en-us/services/machine-learning/
My running command history
1 cd /storage/research/data
2 ls
3 cd Jaya-VSM/
4 ls
5 cd pytorch-vsumm-reinforce-master/
6 ls
7 cd resnet50feature_v5.py
8 python resnet50feature_v5.py
9 pip install sympy
10 python resnet50feature_v5.py
11 pip install imutils
12 python resnet50feature_v5.py
13 pip install torchvision
14 python resnet50feature_v5.py –user
15 pip install torchvision –user
16 python resnet50feature_v5.py
17 pip install torchvision –user
18 pip install torchvision.models.feature_extraction’ –user
19 pip install torchvision.models.feature_extraction –user
20 pip install torchvision
21 python resnet50feature_v5.py
22 conda install torchvision
23 conda install -c conda-forge torchvision
1 tmux new -s
2 tmux new -s
3 tmux new -s phdwork
4 ld
5 ls
6 cd pytorch-vsumm-reinforce-master/
7 ls
8 tmux list-sessions
9 tmux list-sessions
10 cd ..
11 ls
12 tmux list
13 tmux
14 tmux attach -t phdwork
15 tmux attach -t phdwork
16 tmux attach -t phdwork
17 tmux
18 tmux attach -t phdwork
19 tmux attach -t phdwork
20 tmux attach -t phdwork
21 tmux attach -t phdwork
22 tmux attach -t phdwork
23 nvidia-smi
24 docker-images
25 docker images
26 NV_GPU=’4′ nvidia-docker run –rm -it -v /storage/research/:/storage/research/ nvcr.io/nvidia/pytorch
27 NV_GPU=’4′ nvidia-docker run -it -v /storage/research/:/storage/research/ nvcr.io/nvidia/pytorch
28 NV_GPU=’4′ nvidia-docker run -it -v /storage/research/:/storage/research/ nvcr.io/nvidia/pytorch:latest
29 NV_GPU=’4′ nvidia-docker run -it -v /storage/research/:/storage/research/ nvcr.io/nvidia/pytorch:21.03-py3
30 tmux attach -t phdwork
275 export PATH=”/storage/research/data/Jaya-VSM/miniconda3/bin:$PATH”
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorchTo change the default GPU device:
CUDA_VISIBLE_DEVICE = <GPU NUMBER>
for example: CUDA_VISIBLE_DEVICE = 7
If you want to run your code on the another GPU,it assumes that your machine has more than two GPUs, You can do the following trick.
- run this line of code in tmux: CUDA_VISIBLE_DEVICES=1 python YourScript.py
- example: CUDA_VISIBLE_DEVICES=4 python run_example.py
Note: By default, tensorflow uses the first GPU, so with above trick, you can run your another code on the second GPU, separately.
Command to check OS versions on Linux
cat /etc/os-release
Command to see sessions
tmux ls
Command to delete Sessions
tmux kill-session -t <Session_name>
Command to list all conda environments
conda env list
Command to delete conda Environments
conda remove –name <ENV_NAME> –all
Create Clone Conda Environment
conda create –name bennettclone –clone bennett
here bennett is the environment , which i am cloning, first do ‘conda activate bennett’, then clone it using this command.
Install Anaconda/Miniconda to storage
Anaconda3-2024.02-1-Linux-x86_64.sh -u -p /storage/research/data/<your folder>
Environment setup:
- tmux new -s phdwork
- download miniconda: https://docs.conda.io/en/latest/miniconda.html
- tranfer miniconda to home/dgxuser
- provide exceutable permissions in ‘home’: chmod +x Miniconda3-latest-Linux-x86_64.sh
- export PATH=”/storage/research/data/Jaya-VSM/miniconda3/bin:$PATH”
- conda create -n phdwork python=3.9
- source ~/miniconda3/etc/profile.d/conda.sh
- conda activate phdwork
- conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
- Works to pull a pytorch docker : –NV_GPU=’2,3,4′ nvidia-docker run -it -v /storage/research/:/storage/research/ nvcr.io/nvidia/pytorch:21.03-py3
tensorboard+pytorch
conda install pytorch torchvision -c pytorch
conda install matplotlib tensorboard
Graph Visualization
conda install graphviz python-graphviz pip install hiddenlayer

{kind=link}
I’ve learn some excellent stuff here. Certainly price bookmarking for revisiting. I wonder how much effort you put to make any such wonderful informative site.