![You are currently viewing Classical Convolutional Neural Networks[CNN]](https://connectjaya.com/wp-content/uploads/2021/06/Slide7-2.jpg)

Classical CNNs can recognize a person, a car, a building, an animal, a bird, and also can distinguish among these as our eyes and brain do. We are very good in watching, understanding , learning and inferring a scene, it happens in our brain so fast. To Make a computer understand an interpret a scene we need CNNs. These are complex mathematical models which are very good in finding patterns in images, recognizing people, understanding a scene, coloring a black and white image, assisting in medical diagnosis and surgeries and even understanding a document.
Lets look into CNN Timeline.

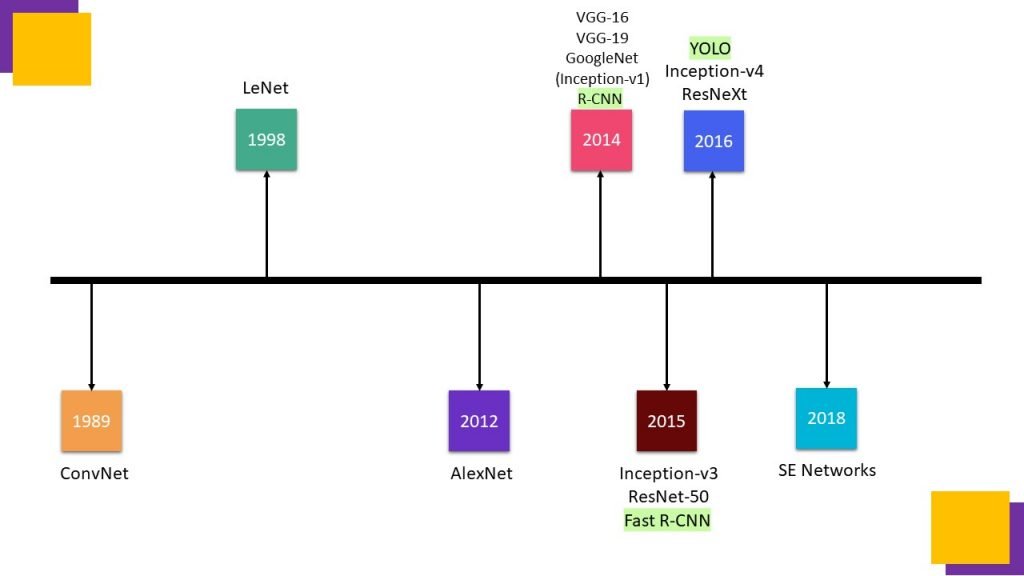
CNN are also called ConvNet, which was initially developed by LeCunn in year 1989 to recognize handwritten digits.
Later in 1998, LeCunn proposed an improved ConvNet architecture called LeNet , which was more accurate in detecting hand written digits, that’s why it was quickly adoped by industry, one of the use cases of LeNet was handwritten digits recognition of bank cheques by utilizing MNIST dataset. It consisted of total 156 trainable parameters.
AlexNet won the 2012 ImageNet competition, where ImageNet dataset had around 15 million high resolution images, 1.2 million for training , 50 thousand for validation and 150 thousand for testing purpose in which 22 thousand classes are labeled. It is very good for any object-detection task. It consisted of total 60 million parameters.
VGGNet was invented by Visual Geometry Group from University of Oxford, It was the 1st runner-up, in ILSVRC ImageNet Large Scale Visual Recognition Competition 2014 in the classification task, which has significant improvement over ZFNet , The winner in 2013 and AlexNet The winner in 2012 ImageNet Challenges. VGG-16 has 130 million trainable parameters whereas VGG-19 has 143 million trainable parameters.
GoogleNet or Inception V1 was the state-of-the-art architecture at ImageNet Large Scale Visual Recognition Competition 2014. Prior to its inception (pun intended), most popular CNNs like LeNet, AlexNet were just stacked convolution layers to deep levels hoping to get better performance. on the other hand, Inception was a complex Network. It used Network in Network approach to push the performance for image classification task. NiN architectures use spatial Multilayer Perceptron(MLP) layers after each convolution to combine features before another layer. The 1×1 convolutions are really helpful in combining convolutional features in better way instead of simply stacking more and more convolutional layers. Total number of trainable parameters in Inception v1 are around 6.7 million , which are pretty less than AlexNet, VGG-16, and VGG-19 with greater speed and accuracy.
The most popular variant of Inception-v1 is Inception-v3, it was the first model to use batch normalization. It also used the factorization method to have more efficient computations. Batch normalization is a technique for training very deep neural networks that standardizes the inputs to a layer for each mini-batch. This has the effect of stabilizing the learning process and dramatically reducing the number of training epochs required to train deep networks.
Another interesting framework named ResNet was developed in year 2015, with model depth of 18, 34, 50, 101, 152 stacked layers, in which ResNet50 consists of 50 layers of ResNet blocks where each block has 2 or 3 convolutional layers, It has 26 million trainable parameters. ResNet was proposed by He et al., who had won the ImageNet competition in 2015. It solved the problem of vanishing gradients in Deep Neural Network architectures by using residual blocks. In DNN architectures, network learns several low/mid/high level features at the end of its layers, whereas In residual learning, instead of trying to learn some features, it try to learn some residual. Residual can be simply understood as subtraction of feature learned from input of that layer. ResNet does this using shortcut cuts or skip connections by directly connecting input of nth layer to some (n+x)th layer. It has proved that training this form of networks is easier than training simple deep convolutional neural networks and the problem of degrading accuracy is also resolved.
Inception-v4 was proposed in year 2016 , which is similar to inception-v3, in which inception block is combined with ResNet block, which is complex in nature but utilize the advantages of residual network as well as inception network. With 43 million parameters
ResNeXt, proposed by Xie et al in year 2016, in which the concept of cardinality is proposed as an essential factor in addition to the dimensions of depth and width. Cardinality is the size of the set of transformations. It has 89 million parameters.
Squeeze and Excitation Network (SE-Network) was proposed by Hu et al. in year 2018. They proposed a new block for the selection of feature-maps (commonly known as channels) preferably for object discrimination task.
Other than classification tasks CNNs are also used for object detection, Image Segmentation, Pose Estimation, Activity Recognition.
Other than classification tasks CNNs are also used for object detection, Image Segmentation, Pose Estimation, Activity Recognition.
R-CNN, Fast R-CNN, Yolo are few examples of pretrained object Detection networks proposed in year 2014, 2015, 2016 respectively.
#SegNet , U-Net, FASTFCN, GATED Shape CNN, Deep Lab, Mask RCNN 2017, 2015, 2019,2019 ,2016 , 2017
#OpenPose 2019, DeepCut 2016, Regional Multi-Person Pose Estimation(RMPE) 2016

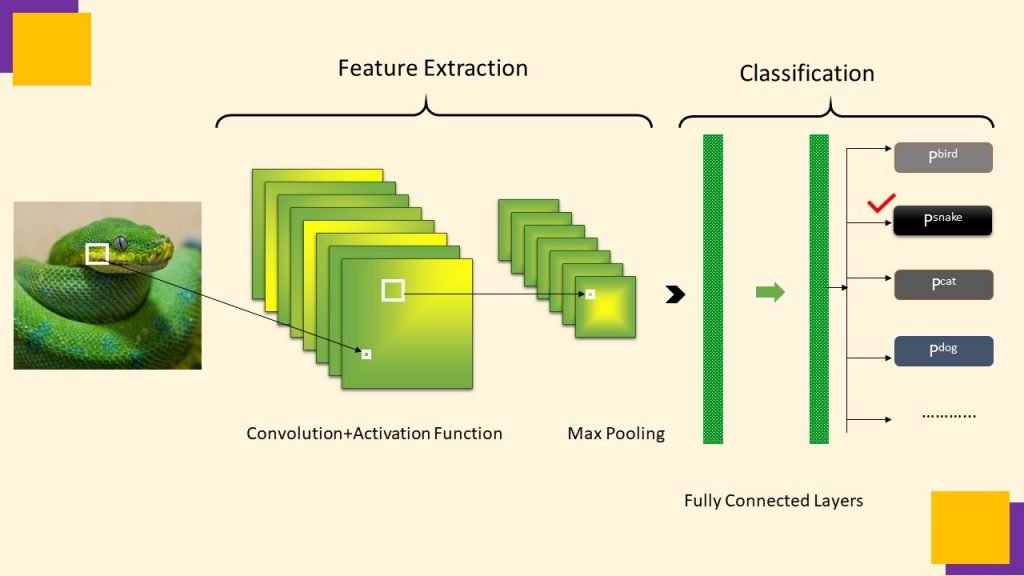
N architectures belong to the family of Deep Neural Networks, consisting of distinct stacked layers to perform specific operations on provided input, to get probability scores at output layer.
On providing image input, CNN extract features from the image, then these features are used for classifying the given image in one of the provided classes, here the image of a green python is getting high probability score at output layer therefore it belongs to the class of snakes.
Features are the building blocks of an image such as edges, ridges, contours, patterns, colors, and their possible combinations. CNN uses Convolution, Max Pooling and fully connected layers to perform classification task.
Let’s Understand each in detail.
2D Convolution In Image Processing
To extract features from an input image a kernel is used for scanning to generate a feature map. For extracting all the features from the image multiple kernels are used to generate multiple feature maps. These feature maps contains numeric values, which are generated after convolution operation.

To understand mathematics behind convolution operation, we first need to understand that an image is made up of intensity values. If an image is a binary image, then it will contain black and white patches, with values 0 and 1 respectively, if it’s a gray scale image it will contain intensity values between 0 to 255. If its a Colored image, then it will contain three channels R, G, B , each channel ranging between 0-255.
Now lets understand convolution operation.
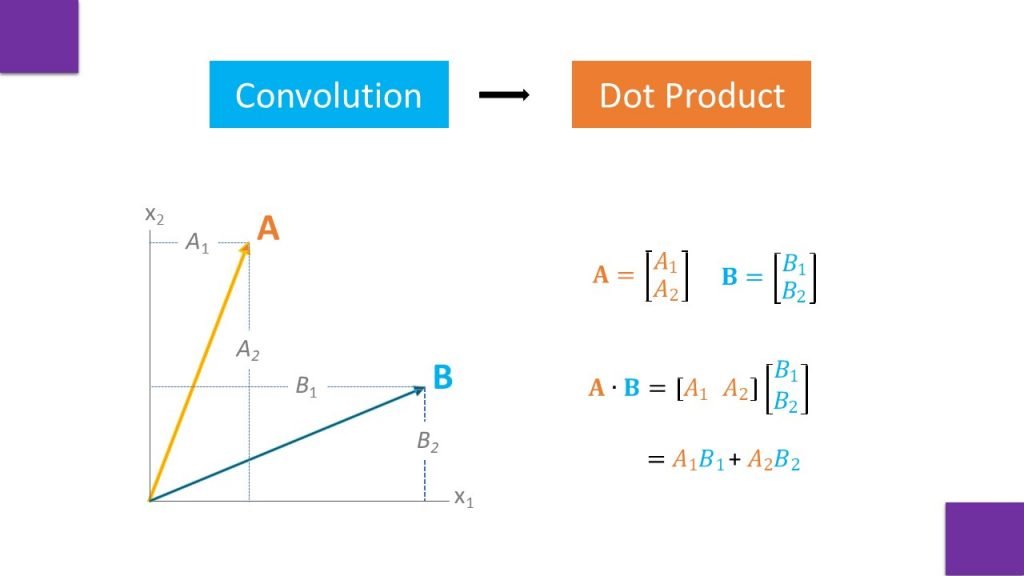
Here we will understand convolution by taking 2×1 matrix A and B, which are simple vectors in 2D plane. To convolve A and B , a dot product is calculated between both the vectors. In convolution same operation of dot product is performed between an image patch and a kernel. Where kernel is defined by a user or it is generated by using random numbers.
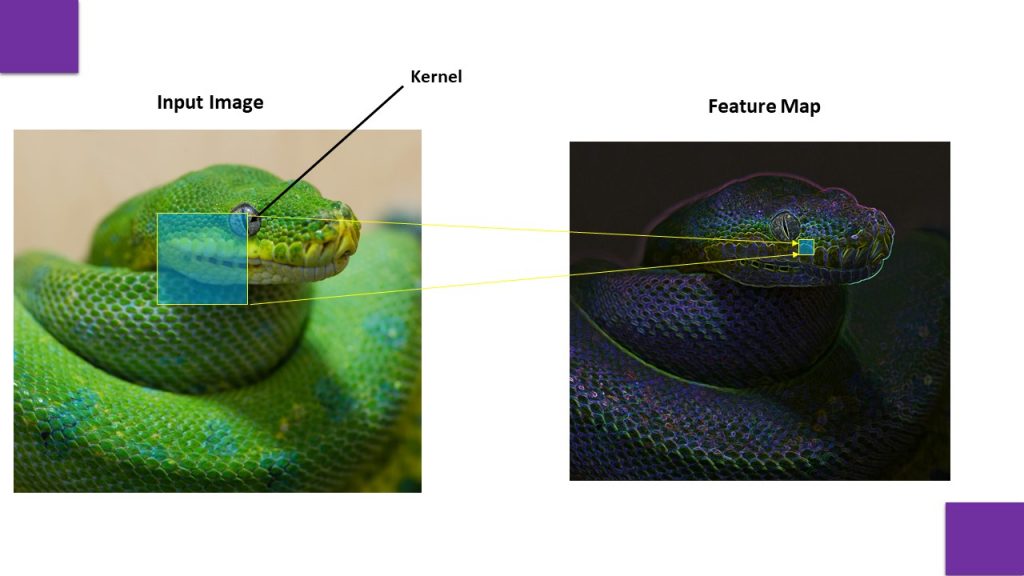
If we look closely the output of a dot product, it is a single value. It means when we apply a kernel over an image patch each time a single value is calculated which capture a distinct feature of that region. Then Relu Activation is applied to filter only positive values of feature map. Lets understand step by step calculation of feature map.
Striding
Here we can see the example of stride -1 and stride -2 kernel. Which resulted in two different feature maps. stride -1 kernel is used in normal practice, but when most of the image is covered with uniform background, stride -2 kernel is used, so that convolution operation will have only useful features.
Padding
When a filter is applied over an image, the obtained feature map size is always less than the image. To Keep feature map of same size as an image padding is used.
Feature Map Calculation
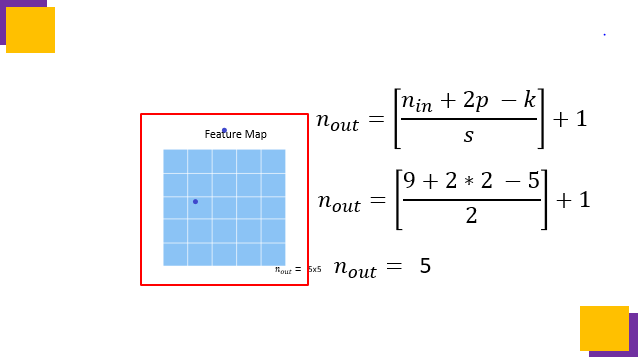
Here I have taken an input image of size 9×9, with padding of 2 px, on which we apply a kernel pf size 5×5 with a stride a 2, then to find out the size of feature map nout following formaula is used.
Max Pooling
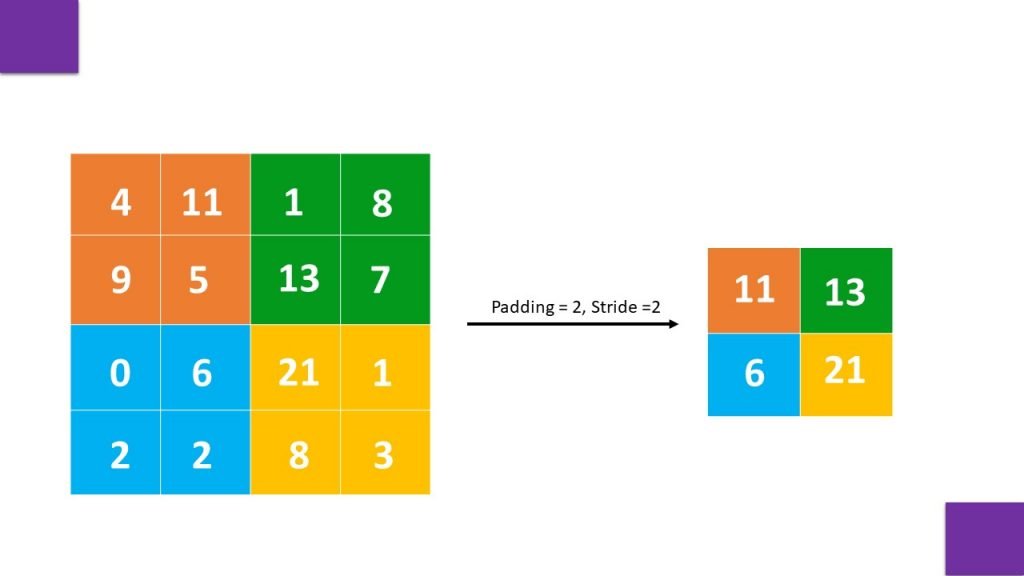
Max pooling operation keeps the max value of 2×2 region of a feature map. It is used to get the most prominent features from the feature map
For hands-on lab along with complete video tutorial watch following video:

{kind=link}