Azure Cognitive Services are cloud-based services that encapsulate AI capabilities. It is a bundle of many individual services to develop sophisticated and intelligent AI Applications.
Cognitive services offer a wide range of prebuilt AI services across multiple categories.
The available cognitive services are encapsulated in four different pillars such as speech, language, decision and vision. These clusters consists of useful services, which are just prebuilt models , if we do not want to build a model from scratch….we can utilize these services using simple API Calls.
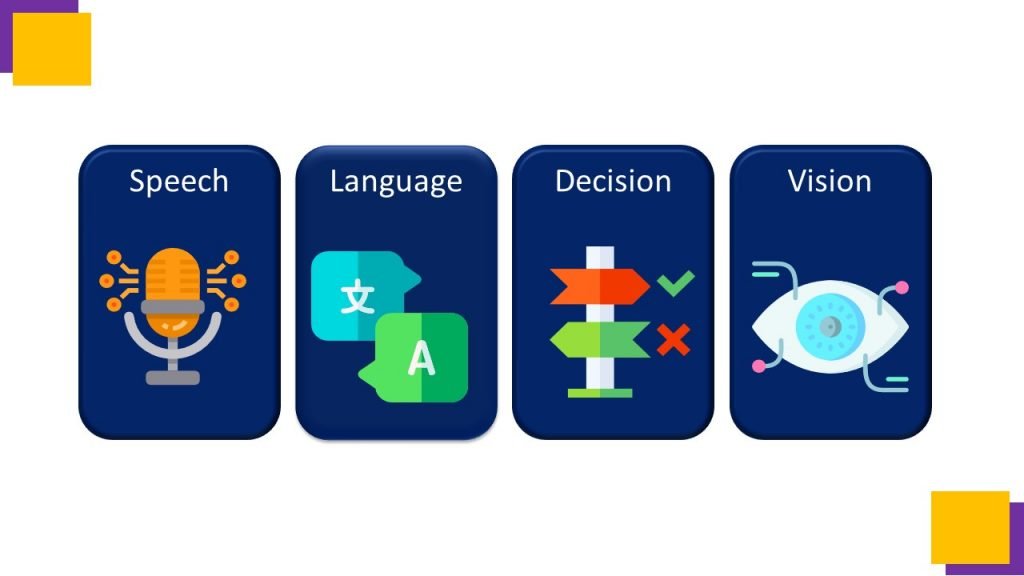
First one is speech service which includes speech to text, text to speech, speech translation and speaker recognition capabilities.
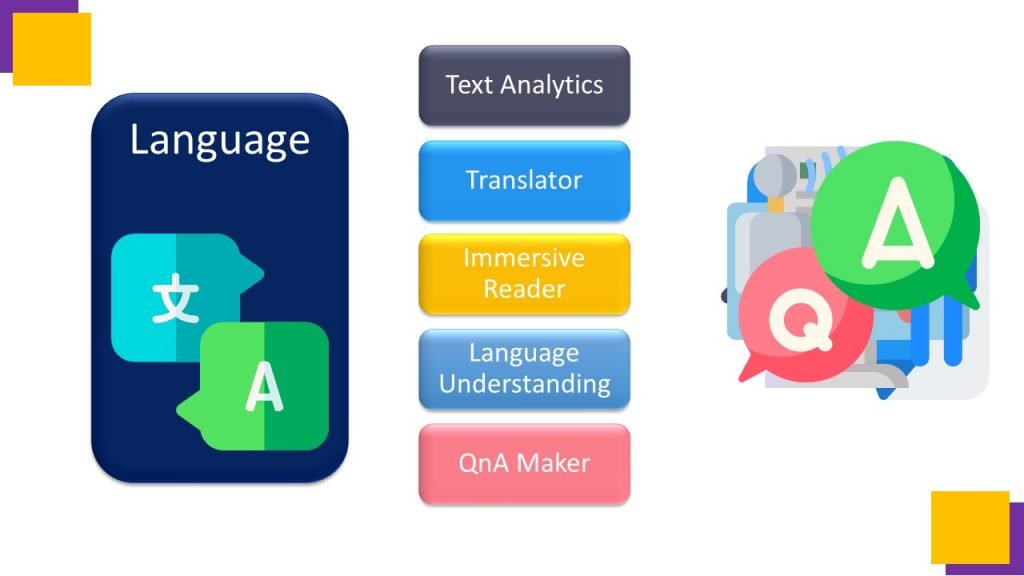
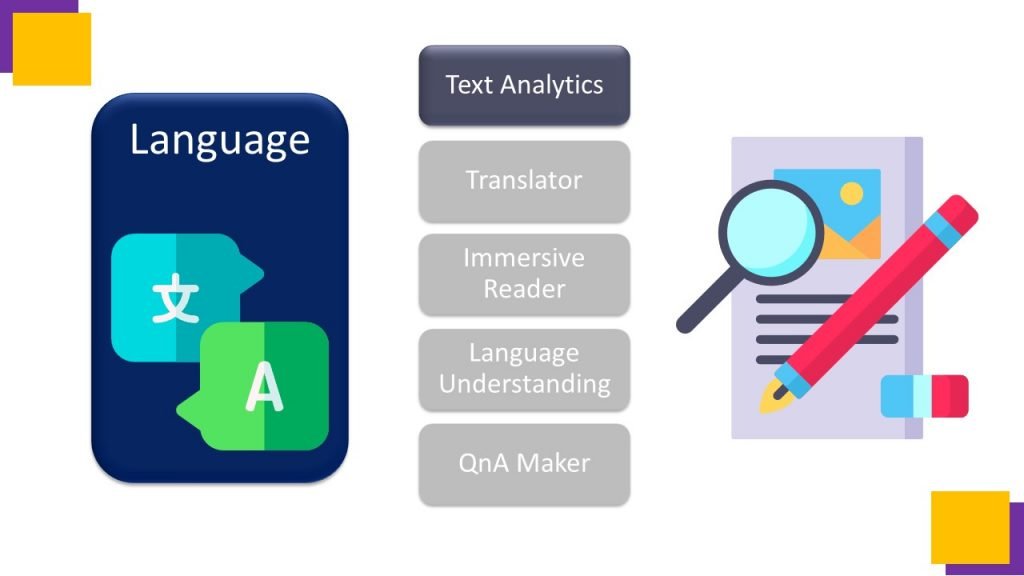
Second is language , which is the cluster of Text Analytics, Translator, Immersive reader, Language Understanding, and Question and answer Maker.
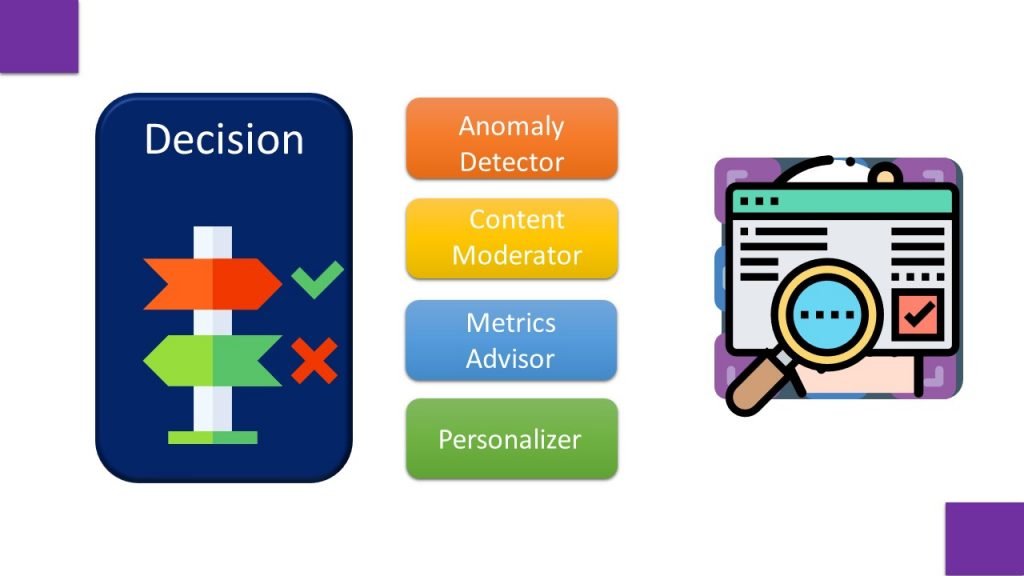
Third one is decision cluster, which consists of Anomaly Detector, Content Moderator, Matrices Advisor and Personalizer.
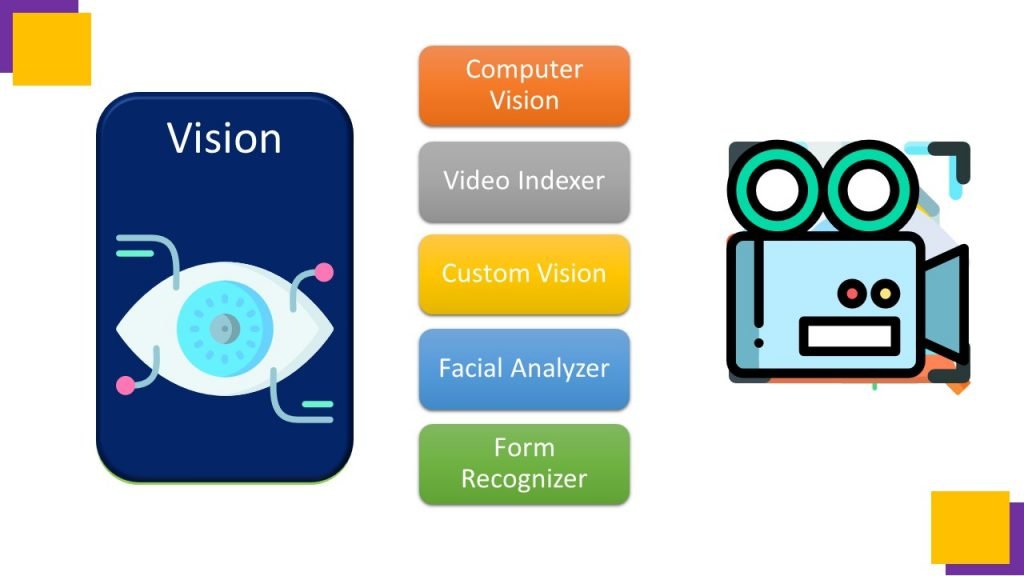
Fourth one is Vision, which consists of Computer vision, Video indexer, Custom vision, Face Analyzer and Form Recognizer. So Lets start with Language,
this cluster is termed as Natural Language Processing, which deals with the types of oral and written communication. In this video I am going to explain Text Analytics in detail with Azure lab experiments.
Getting Started with NLP
The Text Analytics service is designed to extract information from text. This API provides a wide range of services
For example, suppose a travel agency wants to process hotel reviews that have been submitted to the company’s web site. By using the Text Analytics API, we can determine the language of each review in which it is written, we can use this api to find out sentiments of reviews, whether it is positive, negative or neutral. It can also be used to extract key phrases that might indicate the main topics discussed in the review, and named entities, such as places, landmarks, or people mentioned in the reviews.
Hence Text Analytics service can be utilised for following functionalities:
Language Detection, Key Phrase detection, Sentiment Analysis, Named Entity Recognition and Entity Linking.
It provides following functionalities :
Language detection – determines the language in which text is written.
Key phrase extraction – identifies important words and phrases in the text that indicate the main points.
Sentiment analysis – quantifies how positive or negative the text is.
Named entity recognition – detects references to entities, including people, locations, time periods, organizations, and more.
Entity linking – identifies specific entities by providing reference links to Wikipedia articles.
We can provision Text Analytics as a single-service resource, or we can use the Text Analytics API in a multi-service Cognitive Services resource.
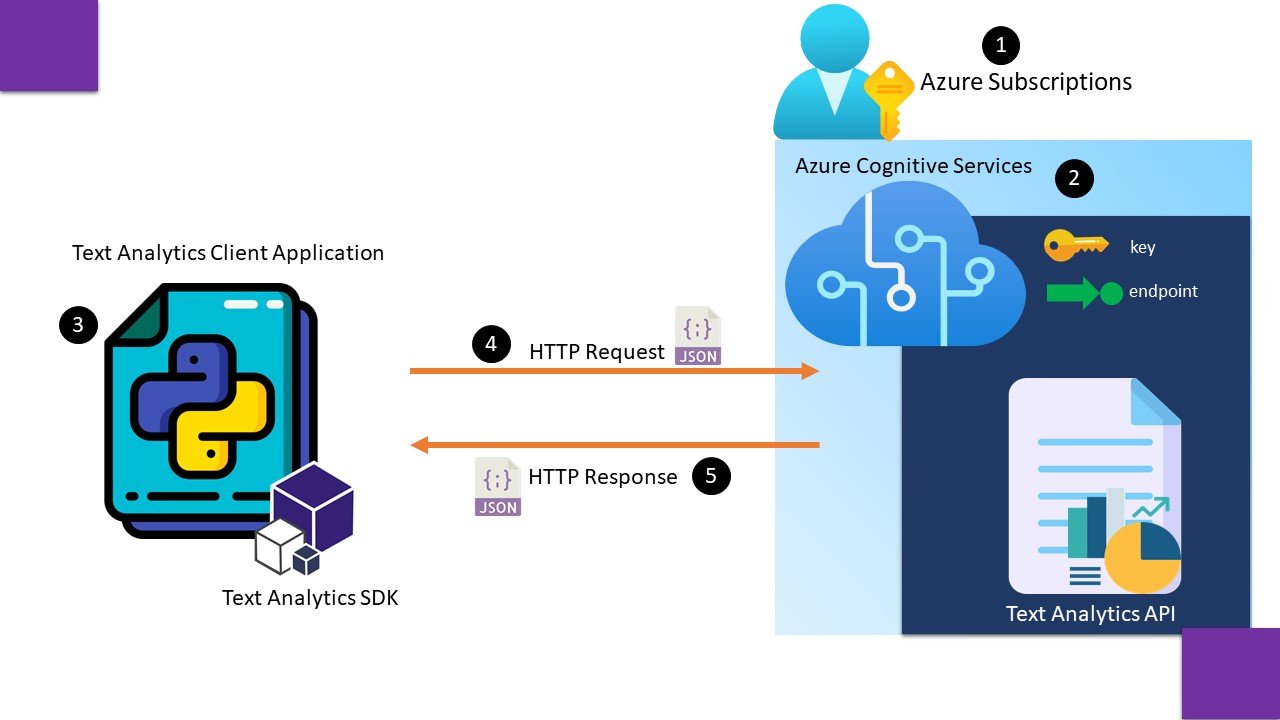
Lets first understand, Cognitive Service Architecture –
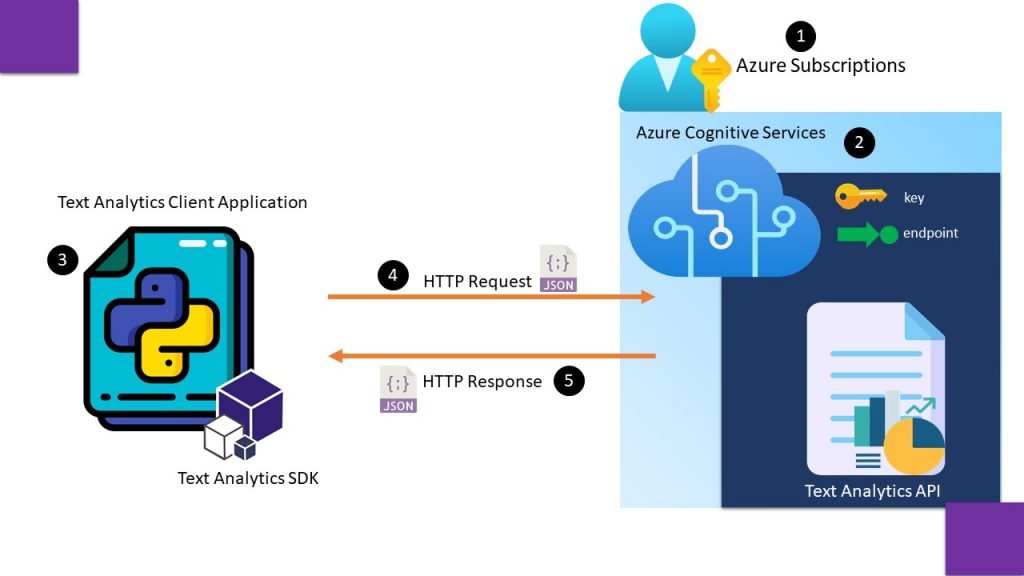
In the first step we create an azure subscription, and register cognitive service resource from the pane of resource providers.
In second step we create an azure cognitive service resource under a resource group and note down keys and endpoints to access this resource.
In third step we install Text Analytics SDK and create a client application to consume Text Analytics API using one of keys and endpoint.
In fourth step a http request is sent in JSON format to consume prebuilt text analytics service. And we collect a response in form of output in fifth step.

Now lets focus on Language Detection API. This API takes text as input and returns language identifiers with a score indicating the strength of the analysis. Text Analytics recognizes up to 120 languages.
This capability is useful for content stores that collect arbitrary text, where language is unknown.
Another scenario could involve a chat bot. If a user starts a session with the chat bot, language detection can be used to determine which language they are using and allow you to configure your bot responses in the appropriate language.
Language detection can detect the language an input text is written in and report a single language code for every document submitted on the request in a wide range of languages, variants, dialects, and some regional/cultural languages. The language code is paired with a confidence score.

Examples

Key phrase extraction API is used to quickly identify the main concepts in text. For example, if the text is : “A Melody of rain is the feast for my brain”, then Key Phrase Extraction will return the main talking points: “rain” and “brain”.

Examples


Sentiment analysis is used to evaluate how positive or negative a text document is, which can be useful in a variety of workloads, such as: •Evaluating a movie, book, or product by quantifying sentiment based on reviews. •Prioritizing customer service responses to correspondence received through email or social media messaging.

Named Entity Recognition identifies entities that are mentioned in the text. Entities are grouped into categories and subcategories, for example: •Person •Location •Date Time •Organization •Address •Email •URL


Entity linking can be used to disambiguate entities of the same name by referencing an article in a a knowledge base. Wikipedia provides the knowledge base for the Text Analytics service. Specific article links are determined based on entity context within the text.



Lab Experiments
- Start Visual Studio Code.
- Open the palette (SHIFT+CTRL+P) and run a Git: Clone command to clone the https://github.com/MicrosoftLearning/AI-102-AIEngineer repository to a local folder (it doesn’t matter which folder).
- When the repository has been cloned, open the folder in Visual Studio Code.
- in the Explorer pane, browse to the 05-analyze-text folder and expand the C-Sharp or Python folder depending on your language preference.
- Right-click the text-analysis folder and open an integrated terminal. Then install the Text Analytics SDK package by running the appropriate command for your language preference:
pip install azure-ai-textanalytics==5.0.0- View the contents of the text-analysis folder, and note that it contains a file for configuration settings:
- Python: .env
- Open the configuration file and update the configuration values it contains to reflect the endpoint and an authentication key for your cognitive services resource. Save your changes.
- Note that the text-analysis folder contains a code file for the client application:
- Python: text-analysis.py
- Open the code file and at the top, under the existing namespace references, find the comment Import namespaces. Then, under this comment, add the following language-specific code to import the namespaces you will need to use the Text Analytics SDK:
Python # import namespaces from azure.core.credentials import AzureKeyCredential from azure.ai.textanalytics import TextAnalyticsClient
In the Main function, note that code to load the cognitive services endpoint and key from the configuration file has already been provided. Then find the comment Create client using endpoint and key[refer the following video till end to understand how to get key and end point], and add the following code to create a client for the Text Analysis API:
Python
Python # Create client using endpoint and key credential = AzureKeyCredential(cog_key) cog_client = TextAnalyticsClient(endpoint=cog_endpoint, credential=credential)
- Save your changes and return to the integrated terminal for the text-analysis folder, and enter the following command to run the program
Python
python text-analysis.py
- Observe the output as the code should run without error, displaying the contents of each review text file in the reviews folder. The application successfully creates a client for the Text Analytics API but doesn’t make use of it. We’ll fix that in the next procedure.
Language Detection
Now that you have created a client for the Text Analytics API, let’s use it to detect the language in which each review is written.
- In the Main function for your program, find the comment Get language. Then, under this comment, add the code necessary to detect the language in each review document:
Python # Get language detectedLanguage = cog_client.detect_language(documents=[text])[0]
- Save your changes and return to the integrated terminal for the text-analysis folder, and enter the following command to run the program:
Python
python text-analysis.py
- Observe the output, noting that this time the language for each review is identified.
Sentiment Analysis
Sentiment analysis is a commonly used technique to classify text as positive or negative (or possible neutral or mixed). It’s commonly used to analyze social media posts, product reviews, and other items where the sentiment of the text may provide useful insights.
- In the Main function for your program, find the comment Get sentiment. Then, under this comment, add the code necessary to detect the sentiment of each review document:
Python
Python
# Get sentiment
sentimentAnalysis = cog_client.analyze_sentiment(documents=[text])[0]
print("\nSentiment: {}".format(sentimentAnalysis.sentiment))
- Save your changes and return to the integrated terminal for the text-analysis folder, and enter the following command to run the program:
Python
python text-analysis.py
- Observe the output, noting that the sentiment of the reviews is detected.
Key Phrase Extraction
It can be useful to identify key phrases in a body of text to help determine the main topics that it discusses.
- In the Main function for your program, find the comment Get key phrases. Then, under this comment, add the code necessary to detect the key phrases in each review document:
Python
Python
# Get key phrase
phrases = cog_client.extract_key_phrases(documents=[text])[0].key_phrases
if len(phrases) > 0:
print("\nKey Phrases:")
for phrase in phrases:
print('\t{}'.format(phrase))
- Save your changes and return to the integrated terminal for the text-analysis folder, and enter the following command to run the program:
Python
python text-analysis.py
- Observe the output, noting that each document contains key phrases that give some insights into what the review is about.
Named Entity Recognition
Often, documents or other bodies of text mention people, places, time periods, or other entities. The text Analytics API can detect multiple categories (and subcategories) of entity in your text.
- In the Main function for your program, find the comment Get entities. Then, under this comment, add the code necessary to identify entities that are mentioned in each review:
Python
Python
# Get entities
entities = cog_client.recognize_entities(documents=[text])[0].entities
if len(entities) > 0:
print("\nEntities")
for entity in entities:
print('\t{} ({})'.format(entity.text, entity.category)
- Save your changes and return to the integrated terminal for the text-analysis folder, and enter the following command to run the program:
Python
python text-analysis.py
- Observe the output, noting the entities that have been detected in the text.
Entity Linking
In addition to categorized entities, the Text Analytics API can detect entities for which there are known links to data sources, such as Wikipedia.
- In the Main function for your program, find the comment Get linked entities. Then, under this comment, add the code necessary to identify linked entities that are mentioned in each review:
Python
Python
# Get linked entities
entities = cog_client.recognize_linked_entities(documents=[text])[0].entities
if len(entities) > 0:
print("\nLinks")
for linked_entity in entities:
print('\t{} ({})'.format(linked_entity.name, linked_entity.url))
- Save your changes and return to the integrated terminal for the text-analysis folder, and enter the following command to run the program:
Python
python text-analysis.py
- Observe the output, noting the linked entities that are identified.

{kind=link}