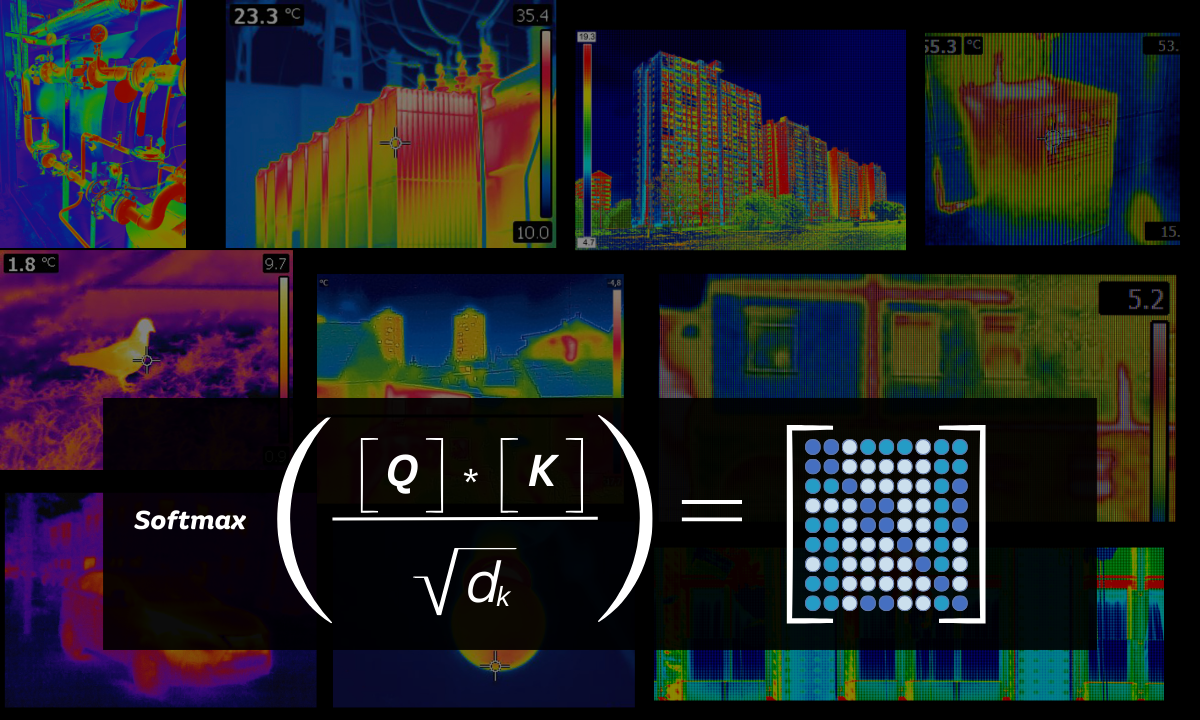
Introduced
The Transformer, a neural network architecture relying solely on self-attention mechanisms. This innovation quickly became the dominant model for various sequence-to-sequence tasks, such as machine translation, text summarization, and question answering.
Table of Contents
What is Attention?
Attention, in the context of machine learning, is a mechanism that allows models to focus on specific parts of the input data while performing a task. Instead of treating all inputs equally, attention mechanisms enable the model to assign varying levels of importance to different parts of the input. This mimics the way human attention works – we prioritize certain information while processing a large amount of data.
Mathematically, attention can be expressed as a weighted sum over the input elements. These weights determine how much attention the model should pay to each element. Let’s break this down further.
Attention Mechanism Basics
Attention mechanisms can be explained using three essential components:
- Query (Q): The query is a vector that represents what the model is currently looking at. It is often derived from the model’s internal state or the previous output.
- Key (K): The key is another vector that represents the elements in the input data. It can be thought of as a set of “pointers” to specific parts of the input.
- Value (V): The value is a vector that represents the actual information associated with each element in the input data.
The Attention Score
The first mathematical step in attention is calculating the attention score, which measures the compatibility or similarity between the query and the keys for each element in the input. This is done using a function, often the dot product or a more complex similarity function. The dot product is a simple choice:
$${Attention Score}(Q, K) = Q \cdot K$$
By calculating the dot product, you’re essentially measuring how well the query and key vectors align. Higher values indicate greater similarity between the query and key for a particular input element.
Attention Weights
To obtain attention weights, the attention scores are usually scaled and normalized using a softmax function. This ensures that the weights sum to 1, allowing the model to allocate its attention effectively:
$${Attention Weight}(Q, K) = \frac{e^{\text{Attention Score}(Q, K)}}{\sum_{i} e^{\text{Attention Score}(Q, K_i)}}$$
Here, ( K_i ) represents all the keys in the input sequence. The softmax function assigns higher weights to elements with higher similarity to the query.
Weighted Sum (Context Vector)
The final step in attention is the weighted sum of the values using the attention weights. This results in a context vector that encapsulates the relevant information from the input data:
$${Context Vector}(Q, V) = \sum_{i} \text{Attention Weight}(Q, K_i) \cdot V_i$$
The context vector is what the model uses to make predictions or generate output, effectively capturing the most relevant information from the input.
However, despite its achievements, the Transformer architecture has limitations. It can be computationally intensive to train and deploy, and its performance can be sensitive to the choice of hyperparameters.
Attention In Cybersecurity & VR
In the realm of virtual reality (VR) technology, the persistent challenge of cybersickness continues to hinder its widespread adoption. This phenomenon, marked by varying levels of discomfort and the potential disruption of immersive experiences, has intrigued researchers for years. Despite longstanding interest, the research field has grappled with inconsistent findings concerning the causes and solutions for cybersickness. Furthermore, individual susceptibility to this issue has been largely overlooked, and a comprehensive explanation is still in the works. Addressing this gap, this review undertakes a comprehensive survey that integrates insights from prior review papers and the latest empirical studies involving participants.
The literature scrutinized in this review underscores the practical studies focused on diverse factors contributing to cybersickness, the advantages and disadvantages of measurement methods, cybersickness profiles, and potential solutions to mitigate this problem. Intriguingly, the findings highlight a lack of attention to user susceptibility and gender balance in group studies, raising questions about the congruity of empirical results. In light of these observations, the review concludes by advocating for increased consideration of individual differences and gender balance in future studies. The study also emphasizes the need for more consistent methodologies and encourages researchers to explore these avenues in their empirical investigations.
Tian, N., Lopes, P., & Boulic, R. (2022). A review of cybersickness in head-mounted displays: raising attention to individual susceptibility. Virtual Reality, 26(4), 1409-1441.
Most cited papers in this category are
| Title | Year | Author |
| SecureBERT: A Domain-Specific Language Model for Cybersecurity | 2022 | Aghaei, et.al |
| A systematic synthesis of critical success factors for cybersecurity | 2022 | Yeoh, et.al |
| A deep hybrid learning model for detection of cyber attacks in industrial IoT devices | 2022 | Shahin, et.al |
| Emerging technologies and problem definition uncertainty: The case of cybersecurity | 2021 | Lewallen, et.al |
| Cybersecurity in ports and maritime industry: Reasons for raising awareness on this issue | 2021 | de la Peña Zarzuelo, et.al |
Attention In Deep Learning
In the realm of human cognition and perception, attention stands as a fundamental element, intricately woven into all cognitive processes. Given the limitations of our cognitive capacity to process multiple stimuli simultaneously, attention mechanisms serve as gatekeepers, selecting, modulating, and honing in on information most pertinent to our behavior. This pivotal concept of attention has been a subject of extensive exploration for decades, spanning disciplines such as philosophy, psychology, neuroscience, and computing. Over the past six years, this concept has been notably integrated into the domain of deep neural networks, marking a significant advancement in the field of Deep Learning.
Presently, the pinnacle of Deep Learning is represented by neural attention models across various application domains. This survey meticulously examines and analyzes the progress made in neural attention models, delving into a plethora of architectures. The researchers conducted a systematic review, scrutinizing hundreds of these architectures, pinpointing and dissecting those in which attention has made a substantial impact. Additionally, they have pioneered an automated methodology, publicly accessible, to facilitate the development of reviews in this domain.
By critically assessing 650 scholarly works, the survey delineates the principal applications of attention in convolutional, recurrent networks, and generative models. It identifies recurring patterns and common applications of attention across different subsets, shedding light on its nuanced uses. Furthermore, the study elucidates the influence of attention in diverse application domains, highlighting its role in enhancing the interpretability of neural networks.
Ultimately, the researchers outline emerging trends and potential avenues for further exploration, aiming to provide a concise overview of the key attentional models in this field. Their hope is that this comprehensive review will serve as a roadmap, guiding future researchers in the development of innovative approaches that will propel the field of neural attention models even further.
de Santana Correia, A., & Colombini, E. L. (2022). Attention, please! A survey of neural attention models in deep learning. Artificial Intelligence Review, 55(8), 6037-6124.
Most cited papers in this category are
| Title | Year | Author |
| Intelligent fault diagnosis of rolling bearings under imbalanced data conditions using attention-based deep learning method | 2022 | Li, et.al |
| Attention, please! A survey of neural attention models in deep learning | 2022 | de Santana Correia, et.al |
| A hybrid deep learning architecture for wind power prediction based on bi-attention mechanism and crisscross optimization | 2022 | Shahin, et.al |
| Brain tumor segmentation based on deep learning and an attention mechanism using MRI multi-modalities brain images | 2021 | Ranjbarzadeh, et.al |
| A review on the attention mechanism of deep learning | 2021 | Niu, et.al |
Attention in Neural Machine Translation
In recent times, non-autoregressive (NAR) generation, initially introduced in neural machine translation (NMT) to enhance inference speed, has garnered significant attention within the machine learning and natural language processing communities. Although NAR generation substantially accelerates machine translation inference, it does so at the expense of translation accuracy when compared to its counterpart, autoregressive (AR) generation. To bridge the accuracy gap between NAR and AR generation, numerous models and algorithms have been devised in recent years.
This paper presents a comprehensive survey, offering comparisons and discussions on various non-autoregressive translation (NAT) models from diverse angles. The survey systematically categorizes NAT efforts into several groups, encompassing data manipulation, modeling methods, training criteria, decoding algorithms, and the influence of pre-trained models. Additionally, it briefly explores alternative applications of NAR models beyond machine translation, including grammatical error correction, text summarization, text style transfer, dialogue systems, semantic parsing, and automatic speech recognition.
Furthermore, the paper delves into potential future directions for exploration, addressing issues like releasing the dependency of KD (knowledge distillation), establishing reasonable training objectives, pre-training methods for NAR, and expanding the scope of applications. The overarching goal of this survey is to offer a comprehensive overview, allowing researchers to grasp the latest advancements in NAR generation. It aims to inspire the development of advanced NAR models and algorithms, guiding industry practitioners in selecting suitable solutions for their specific applications.
Xiao, Y., Wu, L., Guo, J., Li, J., Zhang, M., Qin, T., & Liu, T. Y. (2023). A survey on non-autoregressive generation for neural machine translation and beyond. IEEE Transactions on Pattern Analysis and Machine Intelligence.
Most cited papers in this category are
| Title | Year | Author |
| Retrosynthetic reaction pathway prediction through neural machine translation of atomic environments | 2022 | Ucak, U. V., Ashyrmamatov, I., Ko, J., & Lee, J., et.al |
| Region-attentive multimodal neural machine translation | 2022 | Zhao, Y., Komachi, M., Kajiwara, T., & Chu, C., et.al |
| How neural machine translation works | 2022 | Pérez-Ortiz, J. A., Forcada, M. L., & Sánchez-Martínez, F., et.al |
| A Survey on Document-level Neural Machine Translation: Methods and Evaluation | 2021 | Maruf, S., Saleh, F., & Haffari, G, et.al |
| Neural machine translating from natural language to SPARQL | 2021 | Yin, X., Gromann, D., & Rudolph, S, et.al |
Attention in Genome Data Analysis
The rapid evolution of deep learning, specifically involving transformer-based architectures and attention mechanisms, has brought about revolutionary changes in various domains, including bioinformatics and genome data analysis. Genome sequences, akin to language texts in their structure, have paved the way for applying techniques successful in natural language processing to genomic data. This comprehensive review critically examines the latest advancements in applying transformer architectures and attention mechanisms to genome and transcriptome data, emphasizing the evaluation of these techniques’ strengths and weaknesses in the realm of genome data analysis.
Given the swift progress in deep learning methods, it is crucial to continuously assess and contemplate the current state and future trajectory of research in this field. Thus, this review serves as a timely resource, catering to both experienced researchers and newcomers, offering an extensive perspective on recent developments and showcasing cutting-edge applications in the domain. Additionally, this review paper aims to pinpoint potential areas for future exploration by critically analyzing studies conducted between 2019 and 2023, thereby laying the groundwork for further research initiatives.
Choi, S. R., & Lee, M. (2023). Transformer Architecture and Attention Mechanisms in Genome Data Analysis: A Comprehensive Review. Biology, 12(7), 1033.
Most cited papers in this category are
| Title | Year | Author |
| Shared genetics between autism spectrum disorder and attention-deficit/hyperactivity disorder and their association with extraversion | 2022 | Baranova, A., Wang, J., Cao, H., Chen, J. H., Chen, J., Chen, M., … & Zhang, F., et.al |
| Integrative multi-omics analysis of genomic, epigenomic, and metabolomics data leads to new insights for Attention-Deficit/Hyperactivity Disorder | 2022 | Baranova, A., Wang, J., Cao, H., Chen, J. H., Chen, J., Chen, M., … & Zhang, F., et.al |
| Chromatin interaction–aware gene regulatory modeling with graph attention networks | 2022 | Karbalayghareh, A., Sahin, M., & Leslie, C. S., et.al |
| DeepATT: a hybrid category attention neural network for identifying functional effects of DNA sequences | 2021 | Li, J., Pu, Y., Tang, J., Zou, Q., & Guo, F., et.al |
| Computational Techniques and Tools for Omics Data Analysis: State-of-the-Art, Challenges, and Future Directions | 2021 | Kaur, P., Singh, A., & Chana, I., et.al |
Attention in Medical Image Analysis
With the advancement in hardware computing power and the evolution of deep learning algorithms, a transformative era of “artificial intelligence (AI) + medical image” is unfolding. Modern medical measurement equipment generates a plethora of medical images during clinical processes, enhancing doctors’ diagnostic precision but also increasing their workload. Deep learning technology has emerged as a promising solution, aiming to facilitate auxiliary diagnosis and enhance diagnostic efficiency. Currently, the fusion of deep learning technology with attention mechanisms has become a focal point of research, showcasing remarkable outcomes in various medical image tasks.
This paper conducts a thorough review of attention-based deep learning methods in the realm of medical image analysis. The review commences with a comprehensive survey of literature, analyzing keywords and existing studies. Subsequently, the paper delves into the development and technical intricacies of the attention mechanism. It outlines the applications of this mechanism in medical image tasks such as classification, segmentation, detection, and enhancement. Furthermore, the review addresses persisting challenges, explores potential solutions, and charts the future research directions in this field.
Li, X., Li, M., Yan, P., Li, G., Jiang, Y., Luo, H., & Yin, S. (2023). Deep learning attention mechanism in medical image analysis: Basics and beyonds. International Journal of Network Dynamics and Intelligence, 93-116.
Most cited papers in this category are
| Title | Year | Author |
| Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis | 2022 | Tang, Y., Yang, D., Li, W., Roth, H. R., Landman, B., Xu, D., … & Hatamizadeh, A, et.al |
| Explainable artificial intelligence (XAI) in deep learning-based medical image analysis | 2022 | Van der Velden, B. H., Kuijf, H. J., Gilhuijs, K. G., & Viergever, M. A., et.al |
| Recent advances and clinical applications of deep learning in medical image analysis | 2022 | Chen, X., Wang, X., Zhang, K., Fung, K. M., Thai, T. C., Moore, K., … & Qiu, Y, et.al |
| A survey on incorporating domain knowledge into deep learning for medical image analysis | 2021 | Xie, X., Niu, J., Liu, X., Chen, Z., Tang, S., & Yu, S., et.al |
| Big Self-Supervised Models Advance Medical Image Classification | 2021 | Azizi, S., Mustafa, B., Ryan, F., Beaver, Z., Freyberg, J., Deaton, J., … & Norouzi, M., et.al |
Attention in Computer Vision
In recent years, deforestation’s significant impact on climate change has led researchers to focus on understanding its drivers and developing accurate segmentation maps. In the realm of computer vision, Vision Transformers (ViTs) have demonstrated their superiority over conventional convolutional neural networks (CNNs). However, ViTs face challenges in remote sensing image processing, including increased computational complexity and the requirement for extensive reference data. In response, this paper introduces an enhanced model called TransU-Net++, integrating attention gates, heterogeneous kernel convolution (HetConv), U-Net, and ViTs. The proposed TransU-Net++ specifically targets semantic segmentation for deforestation mapping in South American forest biomes, namely the Atlantic Forest and the Amazon Rainforest.
The TransU-Net++ significantly improves TransU-Net’s performance over the Atlantic Forest dataset, achieving a 4% increase in overall accuracy, 6% improvement in F1-score, and 16% enhancement in recall. Additionally, the model outperforms other segmentation models, including ICNet, ENet, SegNet, U-Net, Attention U-Net-2, R2U-Net, TransU-Net, Swin U-Net, ResU-Net, U-Net+++, and Attention U-Net, by attaining the highest Area under the ROC Curve value (0.921) in the 3-band Amazon forest dataset. These results highlight the effectiveness of TransU-Net++ in addressing the challenges associated with deforestation mapping, making it a promising solution in this domain.
Jamali, A., Roy, S. K., Li, J., & Ghamisi, P. (2023). TransU-Net++: Rethinking attention gated TransU-Net for deforestation mapping. International Journal of Applied Earth Observation and Geoinformation, 120, 103332.
Most cited papers in this category are
| Title | Year | Author |
| Attention mechanisms in computer vision: A survey | 2022 | Guo, M. H., Xu, T. X., Liu, J. J., Liu, Z. N., Jiang, P. T., Mu, T. J., … & Hu, S. M. , et.al |
| Compressing Vision Transformers With Weight Multiplexing | 2022 | Zhang, J., Peng, H., Wu, K., Liu, M., Xiao, B., Fu, J., & Yuan, L., et.al |
| Learn from All: Erasing Attention Consistency for Noisy Label Facial Expression Recognition | 2022 | Zhang, Y., Wang, C., Ling, X., & Deng, W, et.al |
| Fashion Meets Computer Vision: A Survey | 2021 | Cheng, W. H., Song, S., Chen, C. Y., Hidayati, S. C., & Liu, J, et.al |
| Efficient Attention: Attention With Linear Complexities | 2021 | Shen, Z., Zhang, M., Zhao, H., Yi, S., & Li, H. , et.al |
Attention in Fault Diagnosis
In recent years, the application of Attention Mechanism in the domain of mechanical fault diagnosis has gained significant traction, emerging as a vital technique for scholars and researchers. This mechanism plays a crucial role in enhancing models’ resource allocation efficiency, improving remote information capture capabilities, and significantly boosting the performance of models for various equipment health management tasks, such as fault classification and life prediction. Despite the fruitful outcomes in machinery-related research, there is a notable absence of comprehensive reviews in this area.
To address this gap and aid future scholars in swiftly understanding and selecting appropriate techniques, this paper conducts a thorough review of relevant research and applications concerning Attention Mechanism in Intelligent Fault Diagnosis of Machinery. Utilizing methods outlined in existing literature, the paper systematically classifies and analyzes these techniques from multiple perspectives. The technologies are categorized into three groups: Recurrent-based, Convolution-based, and Self-attention-based. Each attention technique and its specific application scenarios are elaborately described.
Additionally, the paper provides a detailed summary of the advantages and disadvantages associated with various Attention Mechanism techniques. It further explores potential future directions in the mechanistic field, fostering an understanding of emerging trends. The overarching aim of this paper is to serve as a comprehensive reference for researchers, enabling them to navigate this complex landscape and discover promising avenues for further research in the realm of Intelligent Fault Diagnosis of Machinery.
Lv, H., Chen, J., Pan, T., Zhang, T., Feng, Y., & Liu, S. (2022). Attention mechanism in intelligent fault diagnosis of machinery: A review of technique and application. Measurement, 111594.
Most cited papers in this category are
| Title | Year | Author |
| Attention mechanism in intelligent fault diagnosis of machinery: A review of technique and application | 2022 | Lv, H., Chen, J., Pan, T., Zhang, T., Feng, Y., & Liu, S., et.al |
| Fault diagnosis for small samples based on attention mechanism | 2022 | Zhang, X., He, C., Lu, Y., Chen, B., Zhu, L., & Zhang, L., et.al |
| Rolling Bearing Fault Diagnosis Method Base on Periodic Sparse Attention and LSTM | 2022 | An, Y., Zhang, K., Liu, Q., Chai, Y., & Huang, X. , et.al |
| Motor fault diagnosis using attention mechanism and improved adaboost driven by multi-sensor information | 2021 | Long, Z., Zhang, X., Zhang, L., Qin, G., Huang, S., Song, D., … & Wu, G., et.al |
| A hybrid attention improved ResNet based fault diagnosis method of wind turbines gearbox | 2021 | Zhang, K., Tang, B., Deng, L., & Liu, X., et.al |
Attention in Image Captioning
The task of image captioning, bridging computer vision and natural language processing, involves generating descriptive text for images. This task extends the concept of object detection to create detailed textual descriptions beyond single-word labels. While recent research in image captioning primarily focuses on deep learning methods, specifically Encoder-Decoder models using Convolutional Neural Network (CNN) features, there has been limited exploration of leveraging object detection features to enhance caption quality.
This paper introduces a novel attention-based Encoder-Decoder architecture that utilizes convolutional features extracted from a CNN model (Xception) pretrained on ImageNet, along with object features from the YOLOv4 model pretrained on MS COCO. The paper also introduces a unique positional encoding method called the “importance factor” for object features. The proposed model was evaluated on the MS COCO and Flickr30k datasets, and its performance was compared to similar studies in the field. Notably, the new feature extraction approach resulted in a significant 15.04% improvement in the CIDEr score, highlighting the effectiveness of this method in enhancing image captioning quality.
Al-Malla, M. A., Jafar, A., & Ghneim, N. (2022). Image captioning model using attention and object features to mimic human image understanding. Journal of Big Data, 9(1), 1-16.
Most cited papers in this category are
| Title | Year | Author |
| Neural attention for image captioning: review of outstanding methods | 2022 | Zohourianshahzadi, Z., & Kalita, J. K., et.al |
| Sequential Transformer via an Outside-In Attention for image captioning | 2022 | Wei, Y., Wu, C., Li, G., & Shi, H. , et.al |
| Relation constraint self-attention for image captioning | 2022 | Ji, J., Wang, M., Zhang, X., Lei, M., & Qu, L., et.al |
| Divergent-convergent attention for image captioning | 2021 | Yan, C., Hao, Y., Li, L., Yin, J., Liu, A., Mao, Z., … & Gao, X, et.al |
| Task-Adaptive Attention for Image Captioning | 2021 | Yan, C., Hao, Y., Li, L., Yin, J., Liu, A., Mao, Z., … & Gao, X., et.al |
Attention in Sentiment Analysis
In the realm of sentiment analysis, Aspect-based Sentiment Analysis (ABSA) focuses on determining the sentiment polarity (positive, negative, or neutral) associated with specific aspects or attributes mentioned in a sentence. Previous studies in this area have primarily concentrated on extracting aspect-sentiment polarity pairs using dependency trees but often overlooked edge labels and phrase details.
In this paper, the authors propose a novel approach called the phrase dependency graph attention network (PD-RGAT) for ABSA. This network is a relational graph attention model built upon the phrase dependency graph, which amalgamates directed dependency edges and phrase information. The researchers conducted experiments utilizing two pre-training models, GloVe and BERT. The results, obtained from benchmarking datasets including Twitter, Restaurant, and Laptop, showcase that PD-RGAT performs comparably well with various state-of-the-art models. Moreover, the study emphasizes the effectiveness of the graph convolutional structure derived from the phrase dependency graph, as it captures both syntactic information and short and long-range word dependencies. Notably, the incorporation of directed edge labels and phrase information enhances the model’s ability to capture aspect-sentiment polarities in the ABSA task.
Wu, H., Zhang, Z., Shi, S., Wu, Q., & Song, H. (2022). Phrase dependency relational graph attention network for Aspect-based Sentiment Analysis. Knowledge-Based Systems, 236, 107736.
Most cited papers in this category are
| Title | Year | Author |
| Sentiment analysis based on aspect and context fusion using attention encoder with LSTM | 2022 | Soni, J., & Mathur, K., et.al |
| Phrase dependency relational graph attention network for Aspect-based Sentiment Analysis | 2022 | Wu, H., Zhang, Z., Shi, S., Wu, Q., & Song, H. , et.al |
| Convolutional attention neural network over graph structures for improving the performance of aspect-level sentiment analysis | 2022 | Phan, H. T., Nguyen, N. T., & Hwang, D., et.al |
| Attention-Emotion-Enhanced Convolutional LSTM for Sentiment Analysis | 2021 | Huang, F., Li, X., Yuan, C., Zhang, S., Zhang, J., & Qiao, S., et.al |
| ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis | 2021 | Basiri, M. E., Nemati, S., Abdar, M., Cambria, E., & Acharya, U. R., et.al |
More Applications of Attention Mechanisms
Attention mechanisms are incredibly versatile and have found applications in a wide range of machine learning tasks, including:
- Machine Translation: Attention mechanisms in sequence-to-sequence models like the Transformer have greatly improved the quality of machine translation by allowing the model to focus on relevant words during translation.
- Image Captioning: They help generate descriptive captions for images by attending to different regions of the image as it generates each word of the caption.
- Question Answering: In tasks like question answering, attention mechanisms can be used to identify which parts of a passage are most relevant to a given question.
- Sentiment Analysis: They enable models to attend to specific words or phrases in a sentence to determine sentiment, making sentiment analysis more accurate.
This comprehensive review explores the Transformer architecture, delving into its fundamental components, applications, and limitations. The Transformer comprises an encoder and a decoder, both equipped with self-attention layers, enabling the model to grasp long-range dependencies in input sequences. Additionally, positional encoding ensures the model understands token order, crucial for tasks like machine translation, while layer normalization stabilizes the training process.
Recent advancements in Transformer research have addressed some challenges
- Efficient Transformers: Techniques like relative positional embedding, as seen in Transformer-XL, reduce the computational burden of self-attention.
- Scalable Transformers: Models like GPT-3, trained on extensive datasets, handle vast amounts of text and code, excelling in tasks like language translation and question answering.
- Hybrid Transformers: Researchers have started integrating Transformers with other neural networks, like recurrent and convolutional networks, resulting in hybrid models achieving top-tier performance across various tasks.
Despite these strides, there are ongoing challenges. Developing Transformers that are energy-efficient for low-power devices remains a priority. Additionally, enhancing Transformers for intricate tasks such as reasoning and planning poses a significant challenge.
Conclusion
the Transformer architecture has transformed the landscape of sequence-to-sequence learning, excelling in tasks like machine translation, text summarization, and question answering. Active research continues, ensuring that Transformers will likely remain the dominant model architecture for sequence-to-sequence tasks in the foreseeable future.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need.

{kind=link}